Wie man Ollama nutzt, um mit jeder Webseite zu chatten

Du hast wahrscheinlich schon die Veränderung bemerkt. ChatGPT ist überall, aber auch die wachsende Unsicherheit drumherum. Was passiert mit den Dokumenten, die du einfügst? Wer liest deine Eingaben? Können dein Arbeitgeber oder deine Kunden erkennen, wann du es benutzt hast?
Das sind berechtigte Fragen. Und es gibt eine wachsende Gruppe von Menschen, die sie stillschweigend nicht mehr stellen, weil sie ihre KI-Umgebung lokal eingerichtet haben.
Genau darum geht es in diesem Beitrag. Wir schauen uns Ollama an, was es ist, wie man es einrichtet, welche Modelle sich lohnen zu verwenden, und dann kommen wir zu dem Teil, der wirklich spannend ist: KI direkt in deinem Browser zu nutzen, um mit jeder Webseite, die du liest, zu interagieren. Keine Abos. Keine Daten verlassen deinen Rechner, sofern du das nicht möchtest.
Egal, ob du Entwickler, Forscher, Journalist bist oder einfach nur neugierig auf KI und kein Fan davon bist, dass jede Eingabe irgendwo gespeichert wird – das hier ist für dich.
Ganz zuerst – was ist Ollama?
Ollama ist ein kostenloses, Open-Source-Tool, mit dem du große Sprachmodelle direkt auf deinem eigenen Computer herunterladen und ausführen kannst. Mac, Windows, Linux – es funktioniert auf allen.
Stell es dir vor wie einen Modell-Manager. Du wählst ein Modell, lädst es einmal herunter, und es läuft dann komplett auf deiner Hardware. Keine Internetverbindung nötig. Keine Nutzungsgebühren. Kein Drittanbieterserver, der deine Anfragen verarbeitet.
Als ChatGPT erstmals startete, waren leistungsstarke KI-Modelle nur über Cloud-Dienste zugänglich. Jetzt kannst du vergleichbare Modelle komplett lokal und privat ausführen – oder, wenn du mehr Leistung brauchst, Ollamas Cloud nutzen, ohne das Tool oder deinen Workflow zu wechseln. Mehr dazu gleich.
Der praktische Vorteil ist größer als es klingt. Du kannst Ollama sensible Dokumente, private Notizen, vertrauliche Webseiten füttern, und je nach Modus muss nichts davon irgendwohin übertragen werden. Außerdem zahlst du keine Gebühren pro Token, die sich leise zu einer echten Monatsrechnung summieren.
Wofür nutzen Leute Ollama tatsächlich?
Bevor wir zur Einrichtung kommen, ist es sinnvoll, das an realen Anwendungsfällen festzumachen, denn „KI lokal nutzen“ klingt erstmal abstrakt.
Leute verwenden lokale Modelle für eine erstaunlich breite Palette von Aufgaben: lange Berichte zusammenfassen, E-Mails entwerfen, Code debuggen, recherchieren, ohne dass ihre Anfragen gespeichert werden, Verträge analysieren, Meeting-Notizen verarbeiten. Entwickler nutzen es, um Modellverhalten in einer kontrollierten Umgebung zu testen. Autoren holen sich Feedback zu Entwürfen, ohne Angst, dass ihre Arbeit als Trainingsdaten genutzt wird. Studierende bearbeiten komplexe Themen, ohne ein Abo zu leeren.
Der gemeinsame Nenner ist Kontrolle. Nutzer von Ollama wollen mit KI nach ihren eigenen Bedingungen arbeiten, nicht durch ein Abo-Portal, das Preise ändern, Limits setzen oder Sitzungen loggen kann.
Ollama einrichten
Was du brauchst
Du brauchst keine High-End-Maschine, aber RAM ist wichtig. Wir empfehlen mindestens 16 GB für ein flüssiges Erlebnis mit den meisten Modellen. 8 GB funktionieren technisch, du bist aber auf die kleinsten Modelle beschränkt und die Antwortzeiten können sich zäh anfühlen. Wenn du einen Mac mit Apple Silicon hast, bist du besonders gut aufgestellt, da die einheitliche Speicherarchitektur lokale KI sehr effizient handhabt. Windows und Linux funktionieren ebenfalls super.
Installation
Ollama unterstützt die wichtigsten Plattformen (macOS, Linux, Windows). Der einfachste Weg zur Installation:
# On macOS or Linux
curl -fsSL https://ollama.com/install.sh | sh
# Or use Homebrew on macOS
brew install ollama
# On Windows, download the installer from Ollama’s website https://ollama.com/download/windowsNach der Installation läuft Ollama als lokaler Server im Hintergrund auf Port 11434. Du kannst prüfen, ob es funktioniert, indem du im Browser http://localhost:11434 öffnest – du solltest eine Bestätigungsnachricht sehen.
Dein erstes Modell laden
Öffne ein Terminal und gib ein:
ollama pull llama3.2Das lädt das Llama 3.2 Modell von Meta auf deinen Computer (~2 GB). Der run Befehl erledigt den Download auch automatisch, wenn du direkt eingibst:
ollama run llama3.2Tippe deine Frage ein. Erhalte eine Antwort. Du betreibst jetzt ein leistungsfähiges Sprachmodell, komplett auf deiner eigenen Hardware.
Welches Modell solltest du nutzen?
Ollamas Bibliothek enthält über 100 Modelle, was anfangs überwältigen kann. Hier eine praktische Startempfehlung:
| Modell | Gut für | Benötigter RAM |
|---|---|---|
gemma3:2b |
Ältere oder schwächere Rechner | ~4GB |
llama3.2 |
Allgemeiner Alltagsgebrauch | ~8GB |
mistral |
Geschwindigkeit und Codieren | ~8GB |
deepseek-r1 |
Analyse, Logik, Forschung | ~8GB |
llama3.3:70b |
Maximale lokale Leistung | ~32GB+ |
Wenn du neu anfängst, ist llama3.2 die richtige Wahl. Schnell, vielseitig und läuft komfortabel auf den meisten modernen Laptops.
Die Liste deiner installierten Modelle kannst du mit diesem Befehl prüfen:
ollama listWichtig zu wissen: Diese Modelle haben ein Wissensstichtdatum und keinen Zugriff auf aktuelle Informationen. Für Echtzeit-Inhalte, wie eine Webseite, die du gerade liest, musst du den Kontext direkt zuführen. Genau darauf bauen wir auf.
Was, wenn du ein größeres, leistungsfähigeres Modell brauchst?
Lokale Modelle sind beeindruckend, aber durch deine Hardware begrenzt. Ein 70-Milliarden-Parameter-Modell braucht viel RAM, ein 671-Milliarden-Modell läuft auf einem Privatcomputer schlicht nicht.
Hier kommen Ollamas Cloud-Modelle ins Spiel. Seit Ende 2025 kannst du damit riesige Modelle auf Rechenzentren-Hardware über dieselbe Ollama-Oberfläche nutzen, die du kennst. Gleiche Befehle, gleiche API, gleiche Tools.
ollama run deepseek-v3.1:671b-cloudVerfügbare Cloud-Modelle:
deepseek-v3.1:671b-cloud: eines der leistungsfähigsten Open-Weight-Modelleqwen3-coder:480b-cloud: speziell für Programmieraufgaben gebautgpt-oss:120b-cloudundgpt-oss:20b-cloud: OpenAIs Open-Weight-Modelle
Cloud-Modelle verhalten sich wie lokale. Der einzige Unterschied: Du musst dich zuerst bei ollama.com anmelden:
ollama signinUnd wichtig: Ollamas Cloud speichert deine Daten nicht. Du bekommst also die Power großer Cloud-Modelle ohne die üblichen Privacy-Kompromisse.
Die praktische Konsequenz: Für sensible Arbeiten, bei denen nichts deinen Rechner verlassen soll, verwende lokale Modelle. Für maximale Leistung wechselst du zu Cloud-Modellen. Ollama verbindet beides nahtlos, du musst nur das Modell-Tag mit -cloud wählen.
Der Teil, der deine Arbeit wirklich verändert: Chatten mit Webseiten
Jetzt wird’s spannend.
Ollama für sich ist schon nützlich. Aber es mit deinem Browser zu verbinden, sodass du ihm jede Webseite zeigen und Fragen zum Bildschirminhalt stellen kannst, ist der Punkt, an dem der Workflow vom „coolen Experiment“ zur täglichen Unterstützung wird.
Denk mal drüber nach, was das eröffnet:
- Eine komplexe Forschungsarbeit lesen? Frag das Modell, die Methodik zusammenzufassen, die Ergebnisse in einfache Worte zu fassen oder frag nach kritischen Punkten.
- Preisseite eines Konkurrenten prüfen? Frag nach den Unterscheidungsmerkmalen oder was auffällig fehlt.
- Einen langen Nachrichtenartikel lesen? Lass dir die Kernaussagen geben, prüfen, ob Überschrift und Inhalt übereinstimmen, oder höre Gegenargumente.
- Eine Stellenanzeige ansehen? Frag, ob deine Erfahrung wirklich passt.
- Ein juristisches Dokument oder AGB durchgehen? Hol dir eine verständliche Erklärung, ohne sensible Texte in Cloud-Tools einzufügen.
Alles unter deinen eigenen Bedingungen. Der Seiteninhalt geht nur an das Modell, das du gewählt hast.
Wie du es mit SurfMind machst
SurfMind ist eine Browser-Erweiterung, die genau dafür gebaut wurde. Sie liest den Inhalt der Seite, auf der du gerade bist, und ermöglicht dir tatsächlich, direkt im Browser ein Gespräch darüber zu führen – ohne Kopieren und Einfügen.
Sie unterstützt lokale Ollama-Modelle direkt, sowie Ollamas Cloud-Modelle, und bietet dir einen starken KI-Assistenten, der im ganzen Web nach deinen Regeln arbeitet.
So verbindest du sie:
Schritt 1. Bevor du Ollama startest, aktiviere den Browser-Zugriff einmalig mit diesem Befehl:
# Mac/Linux
OLLAMA_ORIGINS="*" ollama serve
# Windows (PowerShell)
$env:OLLAMA_ORIGINS="*"; ollama serveFehlermeldung "Port 11434 bereits in Benutzung"? Das bedeutet, die Ollama-App läuft bereits im Hintergrund. Beende sie zuerst: auf dem Mac klick auf das Ollama-Symbol in der Menüleiste und wähle Beenden; unter Windows im System-Tray. Dann führe den Befehl erneut aus.
Schritt 2. Installiere SurfMind aus dem Chrome Web Store und öffne es auf einer beliebigen Seite.
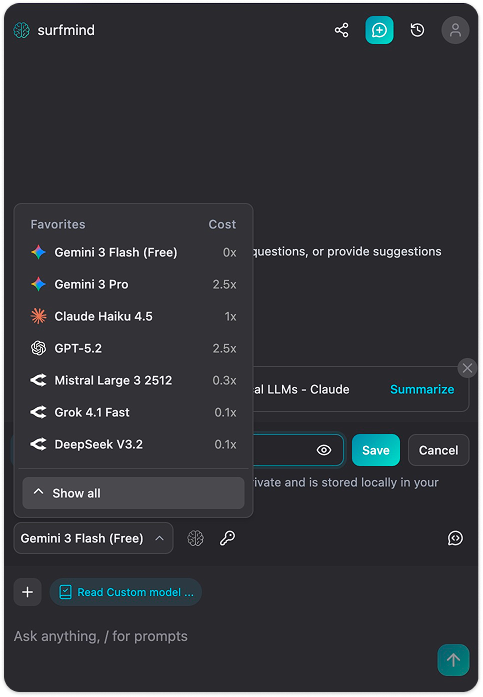
Schritt 3. Klick unten im SurfMind-Panel auf den Modellnamen, um deine Favoriten zu öffnen, und wechsel dann zum Tab Custom.
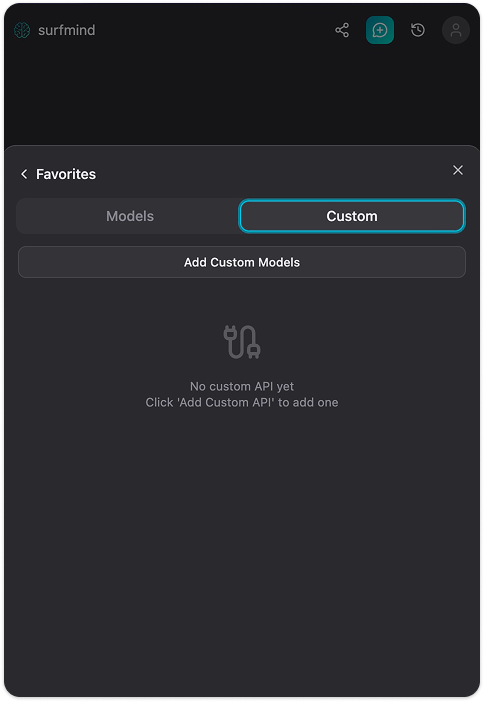
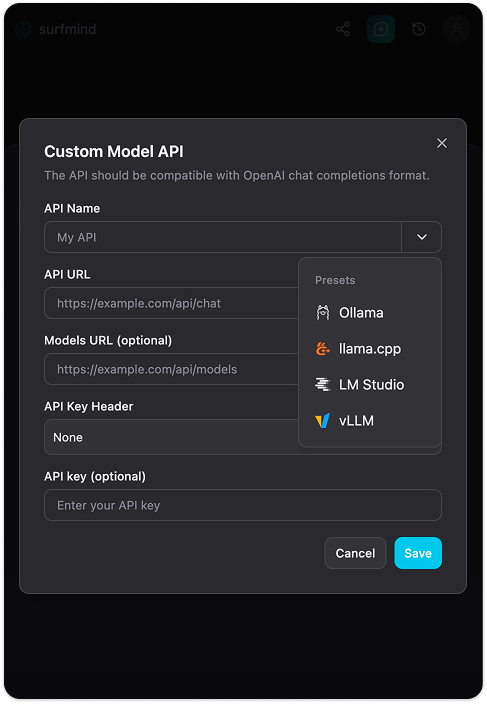
Schritt 4. Klick auf Add Custom Models. Ein Formular „Custom Model API“ erscheint. Klick auf den Dropdown-Pfeil neben dem „API Name“-Feld, du siehst das Menü Presets mit Ollama bereits aufgeführt. Wähle Ollama, dann werden alle Felder automatisch ausgefüllt:
- API URL:
http://localhost:11434/api/chat - Models URL:
http://localhost:11434/api/tags - API Key Header: Keiner
- API Key: (leer lassen)
Schritt 5. Klick auf Save. SurfMind verbindet sich mit deinem lokalen Ollama-Server und lädt die Liste deiner installierten Modelle. Sie erscheinen unter dem Ollama-Bereich und sind zur Auswahl bereit.
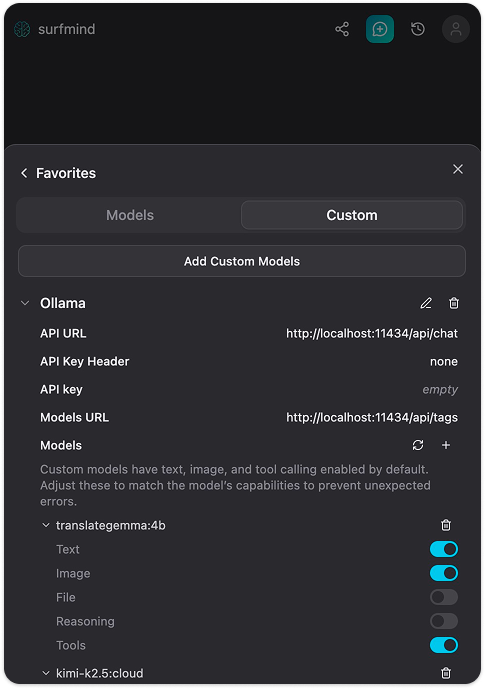
Jetzt navigiere zu einer beliebigen Webseite, öffne SurfMind, wähle dein Ollama-Modell unten aus und stelle Fragen zum Seiteninhalt. Fertig.
Einige praktische Beispiele zum Ausprobieren
Für Forscher und Studierende: Öffne einen wissenschaftlichen Artikel und frag „Was ist hier das Hauptargument?“ oder „Welche Einschränkungen geben die Autoren an?“ Du findest dich in Sekunden zurecht, statt den ganzen Text durchzuscannen.
Für Entwickler: Lade Dokumentation, mit der du arbeitest, und frag konkrete Fragen dazu. Gut, um unbekannte APIs oder Frameworks zu verstehen, ohne den Workflow für ein separates Chatfenster zu unterbrechen.
Für den Business-Einsatz: Punkt auf Geschäftsberichte, Pressemitteilungen, Konkurrentenseiten oder Branchenanalysen. Frag, was auffällt, was fehlt oder welche Fragen sich daraus ergeben. Für tiefgehende Analysen wechsle zum Cloud-Modell.
Für Privatsphäre-Bewusste im Alltag: Jedes Mal, wenn du sonst etwas in ChatGPT kopiert hättest, aber wegen sensibler Inhalte zögerst, ist das hier die bessere Alternative.
Einige ehrliche Hinweise
Kein KI-Tool ist unfehlbar. Modelle liefern gelegentlich selbstsicher klingende, aber falsche Antworten. Das ist eine Einschränkung aller Sprachmodelle, kein Problem, das nur lokal auftaucht. Bei allem, wo Präzision essenziell ist (z. B. Recht, Medizin, Finanzen), solltest du die Ergebnisse als Ausgangspunkt sehen, den du prüfst, nicht als finale Antwort.
Das gesagt, hat die Qualität große Fortschritte gemacht. Kleinere lokale Modelle bewältigen die meisten Alltagsszenarien gut, und wer mehr Power braucht, den schließt Ollamas Cloud-Modelle deutlich die Lücke.
Auf jeden Fall mal ausprobieren – auch nur einmal
Der lokale KI-Bereich ist schneller gewachsen, als die meisten denken. Vor einem Jahr erforderte das noch erheblichen technischen Aufwand. Heute bist du mit zwei Terminal-Befehlen und einer Browser-Erweiterung einem leistungsfähigen KI-Assistenten nahe, der auf jeder Webseite privat, kostenlos und ganz nach deinen Regeln funktioniert.
Wenn du neugierig warst, deine eigene KI-Umgebung zu betreiben, aber dachtest, das sei zu kompliziert, macht Ollama es zugänglich. Installier es heute Nachmittag. Lade ein Modell. Öffne SurfMind beim nächsten Artikel, den du sowieso lesen wolltest. Erlebe, wie es die Erfahrung verändert.
Und wenn du es ausprobierst, sag uns, wofür du es nutzt. Die Anwendungsfälle, die Leute finden, sind immer kreativer als alles, was wir uns ausmalen.
Dein lokales KI-Modell läuft. Setze es jetzt auf jeder von dir besuchten Seite ein.
Neueste Beiträge
Alle anzeigen
Der datenschutzorientierte Leitfaden zur Nutzung von KI-Erweiterungen in Ihrem Browser
Wie Sie KI-Browsererweiterungen verwenden, ohne Ihre Privatsphäre zu gefährden? Entdecken Sie BYOK, lokale Speicherung und granulare Kontrollen, die Ihre Daten schützen.

Wie man AI-Chats nach Obsidian exportiert
Erfahren Sie, wie Sie ausgewählte AI-Chat-Nachrichten mit SurfMind nach Obsidian exportieren und nützliche Gespräche als organisierte Markdown-Notizen in Ihrem Vault speichern.
So exportierst du KI-Chats nach Notion
Lerne, wie du ausgewählte KI-Chatnachrichten mit SurfMind nach Notion exportierst und nützliche Gespräche in organisiertes Wissen verwandelst.