Ollamaを使ってあらゆるウェブページとチャットする方法

あなたもおそらく気づいているでしょう。ChatGPTはどこにでもありますが、それに対する不安もまた広がっています。貼り付けたドキュメントはどうなるのか? 誰があなたのプロンプトを読んでいるのか? 会社やクライアントはあなたが使っていることを知ることができるのか?
これは正当な疑問です。そして、AI環境をローカルに移したことで、静かにその質問をしなくなった人が増えています。
この記事はまさにそのことについてです。Ollamaとは何か、設定方法、どのモデルが使い勝手が良いか、そして本当にワクワクする部分、すなわちブラウザ内で直接AIを使い、読んでいるウェブページに対話的にアクセスする方法を紹介します。サブスクリプション不要。データは自分の端末から出ません(あなたが望まなければ)。
開発者、研究者、ジャーナリスト、AIに興味があって、クエリがどこかに記録されることが気に入らない方に向けた内容です。
まずはじめに — Ollamaとは?
Ollamaは無料のオープンソースツールで、大規模言語モデルを自分のコンピュータ上で直接ダウンロードして実行できます。Mac、Windows、Linuxすべて対応。
モデルマネージャーのようなものです。モデルを選び、一度ダウンロードすれば、その後は完全に自分のハードウェア上で動作します。インターネット接続不要。利用料金なし。第三者のサーバーでクエリを処理することもありません。
ChatGPTが初めて登場した時点では、強力なAIモデルはクラウドサービス経由でしか利用できませんでした。現在は、比較可能なモデルを完全にローカルかつプライベートに実行したり、より高性能が必要な場合はOllamaのクラウドを利用したりすることができます。同じツールやワークフローを変える必要はありません。詳細は後ほど。
実用的なメリットは大きいです。Ollamaには機密文書、プライベートノート、非公開のウェブページを入力できます。使用しているモードによりますが、それらがどこかに送信される必要はありません。また、トークン単位で課金される費用もかからず、地味に積み重なる毎月のコストから解放されます。
実際に人々はOllamaを何に使っているのか?
設定に入る前に、実用例を知っておくと良いでしょう。「AIをローカルで動かす」というのは抽象的に聞こえるかもしれません。
意外に幅広い用途があります。長いレポートの要約、メール作成、コードのデバッグ、クエリが保存されない状態でのリサーチ、契約書の分析、ミーティングノートの処理など。開発者は制御された環境でモデルの挙動テストに使い、作家は原稿へのフィードバックに活用し、学生はサブスクリプションを消費せずに難解なテーマに取り組みます。
共通点は「コントロール」です。Ollamaユーザーは、価格改定やレート制限、セッションログに縛られず、自分の条件でAIと「共に」作業したい人たちです。
Ollamaのセットアップ
必要なもの
最新のマシンは不要ですが、RAMは重要です。大半のモデルを快適に使うには16GBを推奨します。8GBでも動作しますが、小型モデル限定で、応答速度が遅く感じられるかもしれません。Apple Silicon搭載のMacなら、統一メモリアーキテクチャのおかげでローカルAIが非常に効率良く動作します。WindowsやLinuxも問題ありません。
インストール
Ollamaは主なプラットフォーム(macOS、Linux、Windows)をサポートしています。インストールは以下が最も簡単です:
# On macOS or Linux
curl -fsSL https://ollama.com/install.sh | sh
# Or use Homebrew on macOS
brew install ollama
# On Windows, download the installer from Ollama’s website https://ollama.com/download/windowsインストール後、Ollamaはバックグラウンドでポート11434のローカルサーバーを立ち上げます。ブラウザで http://localhost:11434 にアクセスすると確認メッセージが表示されます。
最初のモデルをダウンロード
ターミナルを開いて以下を実行します:
ollama pull llama3.2これでMetaのLlama 3.2モデルがマシンに約2GBでダウンロードされます。runコマンドは自動でダウンロードも処理するので、いきなりこちらを実行しても構いません:
ollama run llama3.2質問を入力すれば答えてくれます。これで能力の高い言語モデルを自分のハードウェアだけで動かせています。
どのモデルを使うべきか?
Ollamaのライブラリは100以上のモデルを扱えるので戸惑いがちですが、実用的なスタートポイントはこちらです:
| モデル | 向いている用途 | 必要RAM |
|---|---|---|
gemma3:2b |
古い機械や低スペック端末向け | 約4GB |
llama3.2 |
一般的な日常利用 | 約8GB |
mistral |
スピードやコーディング作業 | 約8GB |
deepseek-r1 |
分析、推論、リサーチ | 約8GB |
llama3.3:70b |
ローカルでの最大能力 | 32GB以上 |
初めてならllama3.2が最適です。高速でバランスが良く、大半の現代的なノートPCでも快適に動きます。
インストール済みモデルの一覧は以下で確認可能です:
ollama list注意点として、これらのモデルは知識のカットオフ日があり、生の最新情報にはアクセスできません。リアルタイムのコンテンツ、つまりあなたが現在閲覧しているウェブページの内容は直接モデルに渡す必要があります。これがまさにこれから説明する部分です。
より大きく強力なモデルが必要な場合は?
ローカルモデルはハードウェアに制限されます。70Bパラメータモデルは大量のRAMが必要ですし、671Bモデルは個人のコンピュータでは動きません。
そこでOllamaのクラウドモデルが登場します。2025年後半にリリースされ、巨大モデルをデータセンター級のハードウェアで、今お使いの同じOllamaインターフェースで利用可能にします。コマンドもAPIも同じです。
ollama run deepseek-v3.1:671b-cloud利用可能なクラウドモデルの例:
deepseek-v3.1:671b-cloud:最も実力のあるオープンウェイトモデルの一つqwen3-coder:480b-cloud:コーディング向けに設計gpt-oss:120b-cloudとgpt-oss:20b-cloud:OpenAIのオープンウェイトモデル
クラウドモデルはローカルモデルと同様の使い勝手ですが、最初にollama.comでサインインする必要があります:
ollama signin重要なこととして、Ollamaのクラウドはデータを保持しません。そのため通常のプライバシートレードオフなしで大規模クラウドモデルの力を利用できます。
実用的には、機密性の高い作業はローカルモデルで、最大パフォーマンスが必要な場合はクラウドモデルを使い分ける形です。-cloudで終わるモデルタグがクラウドモデルです。
実際の作業の風景が変わる部分:ウェブページとのチャット
ここからが本当に面白いところです。
Ollama単体も便利ですが、ブラウザと連携して、開いているウェブページを指し示し、画面上の内容について質問できるようになると、単なる「クールな実験」ではなく、毎日使いたくなるワークフローに変わります。
これがもたらす利点:
- 難解な研究論文を読んでいる? 研究方法を要約させたり、発見をわかりやすく説明したり、怪しい点を指摘させたり。
- 競合他社の価格ページを見ている? 違いを質問したり、明らかに足りない点を探したり。
- 長いニュース記事を読んでいる? 主要な主張を抽出したり、見出しと本文の整合性を確認したり、反対意見を聞いたり。
- 求人情報を見ている? 自分の経験が合っているかどうか質問したり。
- 法律文書や利用規約を確認している? 機密文書をクラウドに貼り付けずに平易に解説を得たり。
すべてあなたのルールに従って。ページ内容は選んだモデルに渡されます。
SurfMindでの実装方法
SurfMind はまさにこのためのブラウザ拡張機能です。あなたがいるページの内容を読み取り、コピー&ペーストなしでブラウザ内で直接会話できます。
ローカルOllamaモデルとOllamaクラウドモデルの両方をサポートし、どのページでも自分の条件で使えるAIアシスタントです。
接続手順:
Step 1. Ollamaを起動する前に、以下の一度だけのコマンドを実行してブラウザアクセスを有効にします:
# Mac/Linux
OLLAMA_ORIGINS="*" ollama serve
# Windows (PowerShell)
$env:OLLAMA_ORIGINS="*"; ollama serve「ポート11434がすでに使用中」というエラーが出た? Ollamaアプリが裏で動いています。MacならメニューバーのOllamaアイコンからQuitを選択、Windowsならシステムトレイで終了してください。その後もう一度上記コマンドを実行します。
Step 2. ChromeウェブストアからSurfMindをインストールし、任意のページで開きます。
Step 3. SurfMindパネルの下部にあるモデル名をクリックしてお気に入りを開き、Customタブへ切り替えます。
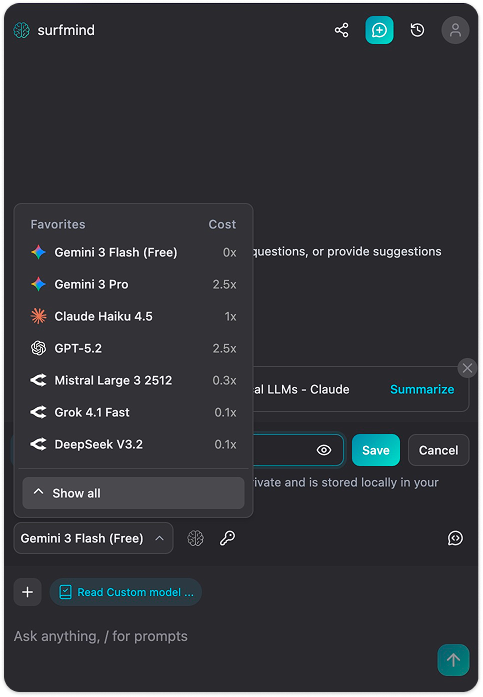
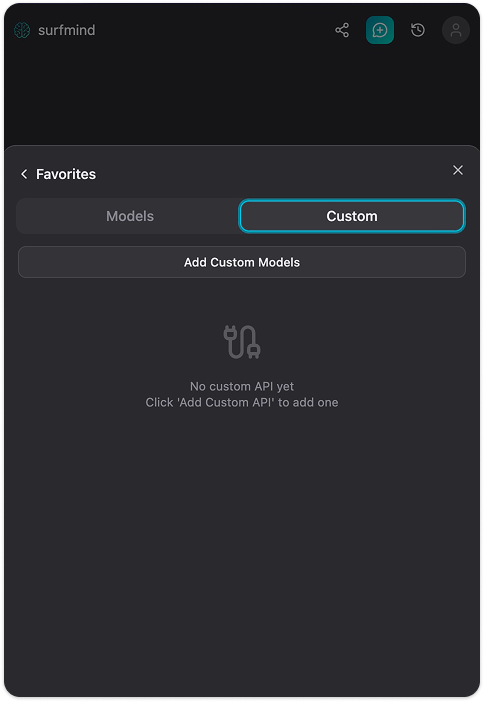
Step 4. Add Custom Modelsをクリック。カスタムモデルAPIのフォームが表示されます。API Nameの横のドロップダウン矢印をクリックするとPresetsにOllamaが表示されます。選択すると各項目に以下が自動入力されます:
- API URL:
http://localhost:11434/api/chat - Models URL:
http://localhost:11434/api/tags - API Key Header: なし
- API Key: 空欄のまま
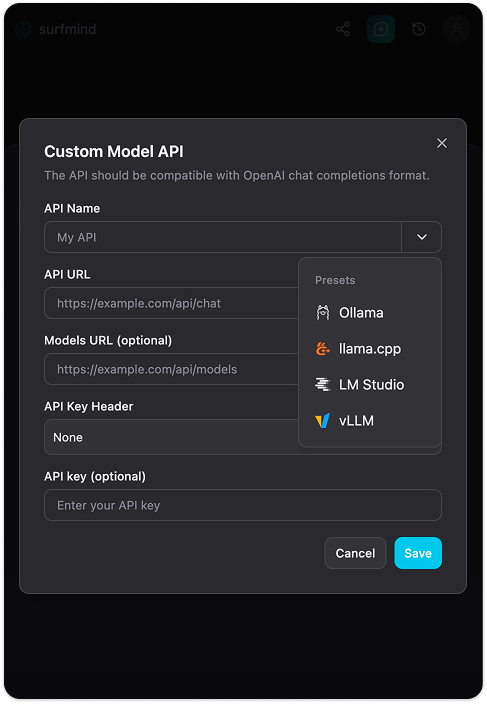
Step 5. Saveを押します。SurfMindがローカルOllamaに接続し、インストール済みモデル一覧を取得して表示します。
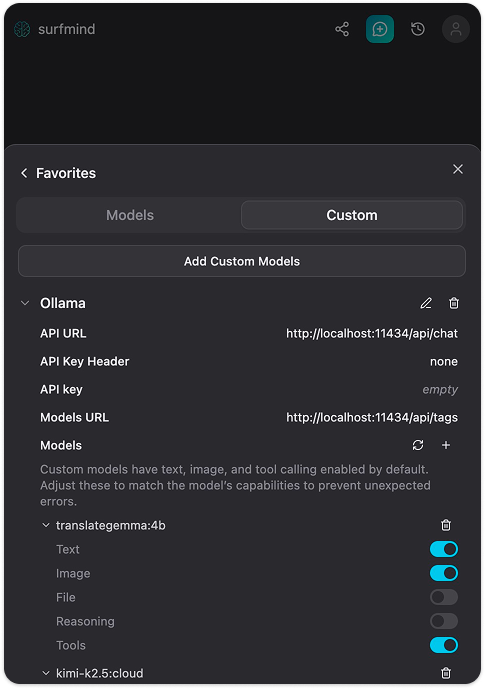
あとは任意のウェブページを開き、SurfMindを起動、下部ピッカーでOllamaモデルを選び、ページ内容について質問を始めれば完了です。
試してみる価値のある実例
研究者や学生向け: どんな学術論文でも「ここでの主要な議論は何か?」「著者が認めている制限は?』と質問すれば、全体を読み飛ばさずに要点をつかめます。
開発者向け: 作業中のドキュメントを開いて特定の質問をしてみてください。慣れないAPIやフレームワークをわざわざ別ウィンドウを開かずスムーズに理解できます。
ビジネス利用: 決算報告、プレスリリース、競合ページ、業界分析に向けて使い、「注目点は?」「足りないものは?」「どんな疑問が生じるか?」と問いかけましょう。深い分析が必要ならクラウドモデルを切り替えるのもおすすめです。
プライバシー重視の一般利用: ChatGPTに貼り付けるのをためらう内容がある時、この方法が最適な代替手段となります。
率直な注意点
どんなAIツールも完璧ではありません。モデルは自信たっぷりだけど間違っている回答を出すことがあります。これは全言語モデル全般の限界で、ローカル特有の問題ではありません。法律分析、医療、金融判断など正確性が重要な場合は、回答を最終答えとして扱わず、検証すべき出発点として扱いましょう。
それでも品質は大きく向上しています。小さめのローカルモデルでも日々のほとんどのタスクをこなせますし、さらに火力が必要なときはOllamaのクラウドモデルがしっかりサポートしてくれます。
一度は試す価値あり
ローカルAIの世界は多くの人が思うより早く成熟しました。一年前は技術的な努力が必須でしたが、今はわずか2つのターミナルコマンドと1つのブラウザ拡張で、どのウェブページでもプライベートに、無料で、自分の条件で動くAIアシスタントを手に入れられます。
独自のAI環境に興味はあったけど難しそうと考えていたなら、Ollamaがそれを手の届くものにします。午後にインストールして、モデルをダウンロードし、次に読む記事でSurfMindを開いてみてください。体験がどのように変わるかを実感できるはずです。
使ってみたら、ぜひあなたがどんな使い方をするか教えてください。使い道はいつも我々が予想するよりも創造的です。
あなたのローカルAIモデルが動いています。ブラウザで閲覧するすべてのページで活用しましょう。
最近の投稿
すべて表示
プライバシー最優先のブラウザAI拡張機能利用ガイド
プライバシーを犠牲にせずにAIブラウザ拡張機能を使うには?BYOK、ローカルストレージ、データを保護する詳細なコントロールについて解説します。

AIチャットをObsidianにエクスポートする方法
SurfMindで選択したAIチャットメッセージをObsidianにエクスポートし、役立つ会話をvault内の整理されたMarkdownノートとして保存する方法を学びましょう。
AI チャットを Notion にエクスポートする方法
SurfMind で選択した AI チャットメッセージを Notion にエクスポートし、役立つ会話を整理された知識に変える方法を紹介します。