Cómo usar Ollama para chatear con cualquier página web

Probablemente hayas notado el cambio que está ocurriendo. ChatGPT está en todas partes, pero también crece la inquietud a su alrededor. ¿Qué ocurre con los documentos que pegas? ¿Quién lee tus indicaciones? ¿Puede tu empleador o clientes saber cuándo lo estás usando?
Son preguntas legítimas. Y hay un número creciente de personas que han dejado de hacerlas silenciosamente porque han trasladado su configuración de IA a local.
De eso trata esta publicación. Te guiaremos por Ollama, qué es, cómo configurarlo, qué modelos vale la pena usar y luego entraremos en la parte que realmente emociona: usar IA directamente dentro de tu navegador para interactuar con cualquier página web que estés leyendo. Sin suscripciones. Sin que los datos salgan de tu máquina, a menos que tú quieras.
Ya seas desarrollador, investigador, periodista o simplemente alguien curioso sobre IA que no le gusta la idea de que cada consulta se registre en algún sitio, esto es para ti.
Lo primero - ¿qué es Ollama?
Ollama es una herramienta gratuita, de código abierto, que te permite descargar y ejecutar grandes modelos de lenguaje directamente en tu computadora. Mac, Windows, Linux, funciona en todos ellos.
Piénsalo como un gestor de modelos. Eliges un modelo, lo descargas una vez y se ejecuta por completo en tu hardware desde ese momento. No se necesita conexión a Internet. No hay costos por uso. No hay un servidor de terceros procesando tus consultas.
Cuando ChatGPT se lanzó por primera vez, los modelos de IA potentes solo eran accesibles a través de servicios en la nube. Ahora puedes ejecutar modelos comparables completamente en local y de forma privada o, si necesitas más potencia, acceder a la nube de Ollama sin cambiar de herramientas ni alterar tu flujo de trabajo. Más sobre eso en un momento.
La ventaja práctica es mayor de lo que parece. Puedes darle a Ollama documentos sensibles, notas privadas, páginas web confidenciales y, dependiendo del modo que uses, nada de eso tiene que viajar a ningún lado. También significa que no pagas tarifas por token que silenciosamente se acumulan en un costo real mensual.
¿Para qué usan las personas Ollama realmente?
Antes de ver la configuración, vale la pena basarlo en casos reales, porque “ejecutar IA localmente” puede sonar abstracto.
La gente usa modelos locales para una sorprendente variedad de cosas: resumir informes largos, redactar correos, depurar código, investigar sin querer que sus consultas se guarden, analizar contratos, procesar notas de reuniones. Los desarrolladores lo usan para probar el comportamiento de modelos en un entorno controlado. Los escritores lo usan para recibir comentarios sobre borradores sin preocuparles que su trabajo se use como datos de entrenamiento. Los estudiantes lo usan para abordar temas complejos sin agotar una suscripción.
El hilo común es el control. Quienes usan Ollama quieren trabajar con IA en sus propios términos, no a través de un portal de suscripción que puede cambiar precios, limitar su velocidad o registrar sus sesiones.
Configurando Ollama
Qué necesitarás
No necesitas una máquina de última generación, pero la RAM importa. Recomendamos al menos 16GB para tener una experiencia fluida con la mayoría de los modelos. 8GB funcionará técnicamente, pero estarás limitado a los modelos más pequeños y los tiempos de respuesta pueden sentirse lentos. Si tienes un Mac con Apple Silicon, estás en una posición particularmente buena, ya que la arquitectura de memoria unificada maneja la IA local muy eficientemente. Windows y Linux también funcionan muy bien.
Instálalo
Ollama soporta las principales plataformas (macOS, Linux, Windows). La manera más fácil de instalar:
# On macOS or Linux
curl -fsSL https://ollama.com/install.sh | sh
# Or use Homebrew on macOS
brew install ollama
# On Windows, download the installer from Ollama’s website https://ollama.com/download/windowsUna vez instalado, Ollama ejecuta un servidor local en segundo plano en el puerto 11434. Puedes verificar que funciona abriendo un navegador y visitando http://localhost:11434; deberías ver un mensaje de confirmación.
Descarga tu primer modelo
Abre una terminal y ejecuta:
ollama pull llama3.2Esto descarga el modelo Llama 3.2 de Meta a tu máquina (~2GB). El comando run también maneja la descarga automáticamente si vas directo a:
ollama run llama3.2Escribe tu pregunta. Obtén una respuesta. Ya estás ejecutando un modelo de lenguaje capaz, completamente en tu propio hardware.
¿Qué modelo deberías usar?
La librería de Ollama tiene más de 100 modelos, lo que puede ser abrumador al principio. Aquí un punto de partida práctico:
| Modelo | Bueno para | RAM necesaria |
|---|---|---|
gemma3:2b |
Máquinas antiguas o con bajo rendimiento | ~4GB |
llama3.2 |
Uso general diario | ~8GB |
mistral |
Velocidad y tareas de codificación | ~8GB |
deepseek-r1 |
Análisis, razonamiento, investigación | ~8GB |
llama3.3:70b |
Máxima capacidad local | ~32GB+ |
Si estás empezando, llama3.2 es la opción adecuada. Es rápido, equilibrado y funciona cómodamente en la mayoría de laptops modernas.
Puedes ver la lista de modelos instalados con este comando:
ollama listUna cosa que vale la pena saber: estos modelos tienen una fecha límite de conocimiento y no tienen acceso a información en vivo. Para contenido en tiempo real, como una página web que estás leyendo en ese momento, tendrás que darles el contexto directamente. Justo hacia donde vamos.
¿Y si necesitas un modelo más grande y poderoso?
Los modelos locales son impresionantes, pero están limitados por tu hardware. Un modelo de 70B parámetros necesita mucha RAM. Un modelo de 671B simplemente no se ejecutará en una computadora personal.
Aquí es donde entran los modelos en la nube de Ollama. Lanzados a finales de 2025, te permiten ejecutar modelos masivos en hardware de grado datacenter usando la misma interfaz de Ollama que ya conoces. Mismos comandos, misma API, mismas herramientas.
ollama run deepseek-v3.1:671b-cloudLos modelos en la nube disponibles incluyen:
deepseek-v3.1:671b-cloud: uno de los modelos con pesos abiertos más capaces disponiblesqwen3-coder:480b-cloud: diseñado para tareas de codificacióngpt-oss:120b-cloudygpt-oss:20b-cloud: modelos de pesos abiertos de OpenAI
Los modelos en la nube funcionan igual que los locales. La única diferencia es que requieren iniciar sesión primero en ollama.com:
ollama signinY, lo importante: la nube de Ollama no retiene tus datos. Así que obtienes el poder de grandes modelos en la nube sin la típica concesión a la privacidad.
La ventaja práctica: usa modelos locales para trabajo sensible donde nada debe salir de tu máquina. Cambia a modelos en la nube cuando necesites máxima capacidad. Ollama maneja ambos sin problemas, solo eliges la etiqueta del modelo que termina en -cloud.
La parte que realmente cambia tu forma de trabajar: chatear con páginas web
Aquí es donde las cosas se ponen interesantes.
Ollama por sí solo es útil. Pero conectarlo a tu navegador, para que puedas apuntar a cualquier página web y hacer preguntas sobre lo que aparece en pantalla, es donde el flujo de trabajo cambia de un “experimento genial” a algo que realmente usarás todos los días.
Piensa en lo que eso desbloquea:
- ¿Leyendo un artículo de investigación denso? Pídele al modelo que resuma la metodología, explique los hallazgos en lenguaje sencillo o señale cualquier cosa que parezca exagerada.
- ¿Revisando la página de precios de un competidor? Pregunta cuáles son los diferenciadores o qué falta de forma notable.
- ¿Leyendo un artículo largo de noticias? Obtén los puntos clave, verifica si el titular coincide con el contenido, escucha el argumento contrario.
- ¿Viendo una oferta de trabajo? Pregunta si tu experiencia realmente coincide con lo que describen.
- ¿Analizando un documento legal o términos de servicio? Obtén un desglose en lenguaje sencillo sin pegar textos sensibles en una herramienta en la nube.
Todo en tus propios términos. El contenido de la página va al modelo que hayas elegido.
Cómo hacerlo con SurfMind
SurfMind es una extensión de navegador creada exactamente para esto. Lee el contenido de la página en la que estás y te permite tener una conversación real al respecto directamente en tu navegador, sin copiar y pegar nada.
Soporta por defecto los modelos locales de Ollama, así como los modelos nube de Ollama, y te da un asistente de IA capaz que funciona en toda la web bajo tus propios términos.
Así se conectan:
Paso 1. Antes de iniciar Ollama, habilita el acceso del navegador con este comando único:
# Mac/Linux
OLLAMA_ORIGINS="*" ollama serve
# Windows (PowerShell)
$env:OLLAMA_ORIGINS="*"; ollama serve¿Error “puerto 11434 ya en uso”? Esto significa que la app Ollama ya se está ejecutando en segundo plano. Ciérrala primero: en Mac, busca el ícono de Ollama en la barra de menús y selecciona Salir; en Windows, encuéntrala en la bandeja del sistema. Luego ejecuta el comando de arriba otra vez.
Paso 2. Instala SurfMind desde Chrome Web Store y ábrelo en cualquier página.
Paso 3. Haz clic en el nombre del modelo en la parte inferior del panel SurfMind para abrir tus Favoritos, luego cambia a la pestaña Personalizados.
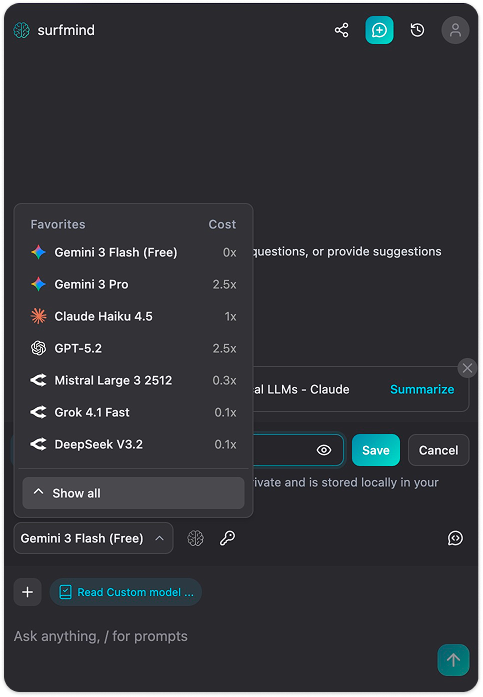
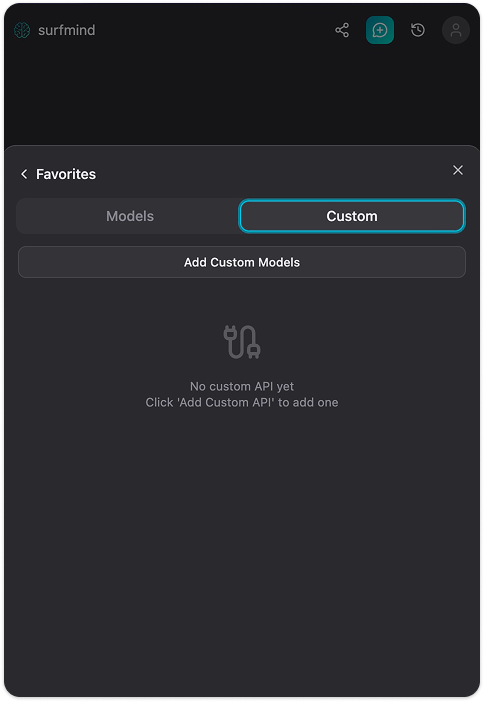
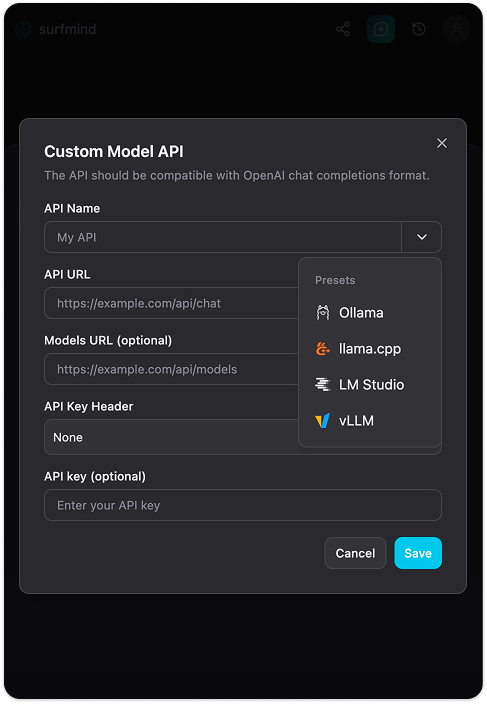
Paso 4. Haz clic en Agregar modelos personalizados. Aparecerá un formulario "API de modelo personalizado". Haz clic en la flecha desplegable junto al campo Nombre de API, verás un menú Preconfiguraciones con Ollama ya listado. Selecciona Ollama y completará todos los campos automáticamente:
- URL de API:
http://localhost:11434/api/chat - URL de modelos:
http://localhost:11434/api/tags - Encabezado de clave API: Ninguno
- Clave API: (dejar vacío)
Paso 5. Haz clic en Guardar. SurfMind se conectará a tu instancia local de Ollama y descargará la lista de modelos instalados. Aparecerán en la sección Ollama, listos para seleccionar.
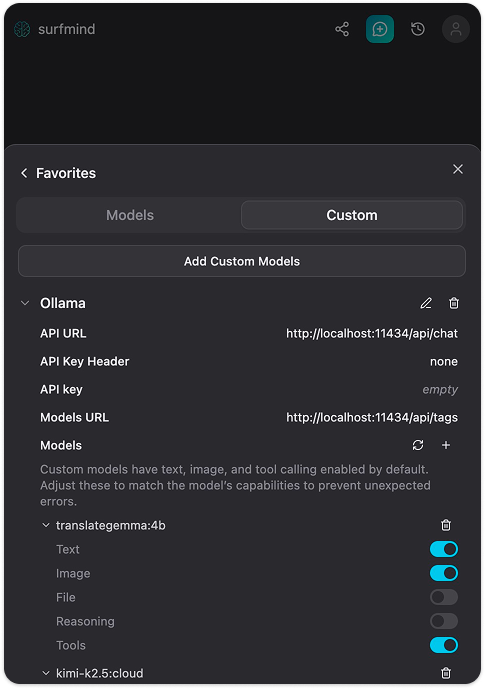
Ahora navega a cualquier sitio web, abre SurfMind, elige tu modelo Ollama desde el selector inferior y comienza a hacer preguntas sobre lo que aparece en la página. Eso es todo.
Algunos ejemplos prácticos para probar
Para investigadores y estudiantes: Abre cualquier artículo académico y pregunta “¿cuál es el argumento principal aquí?” o “¿qué limitaciones reconocen los autores?” Te ubicarás en segundos en lugar de hojear todo el texto para encontrar la sección relevante.
Para desarrolladores: Consulta documentación con la que estás trabajando y haz preguntas específicas sobre ella. Ideal para navegar APIs o frameworks desconocidos sin interrumpir tu flujo para abrir una ventana de chat aparte.
Para uso empresarial: Apúntalo hacia reportes financieros, comunicados de prensa, páginas de competidores o análisis sectorial. Pregunta qué es notable, qué falta o qué dudas genera. Para análisis intensivos, cambia a un modelo en la nube para más profundidad.
Para uso diario preocupado por la privacidad: Cada vez que normalmente pegarías algo en ChatGPT pero dudas por el contenido, esta es la alternativa.
Algunas advertencias honestas
Ninguna herramienta de IA es infalible. Los modelos ocasionalmente generan respuestas seguras que están equivocadas. Esta es una limitación de todos los modelos de lenguaje, no un problema específico local. Para cualquier tema donde la precisión importe, como análisis legales, preguntas médicas o decisiones financieras, trata la salida como un punto de partida que vale la pena verificar, no como una respuesta definitiva.
Dicho esto, la calidad ha avanzado mucho. Los modelos locales más pequeños manejan bien la mayoría de tareas cotidianas y si necesitas más potencia, los modelos en la nube de Ollama reducen considerablemente la brecha.
Vale la pena probarlo, aunque sea una vez
El espacio de IA local ha madurado más rápido de lo que muchos creen. Hace un año requería un esfuerzo técnico considerable. Hoy estás a dos comandos de terminal y una extensión de navegador de tener un asistente de IA capaz que funciona en cualquier página web de forma privada, gratis y completamente en tus propios términos.
Si tenías curiosidad por montar tu propio entorno de IA pero pensabas que era muy complicado, Ollama es lo que lo hace accesible. Instálalo esta tarde. Descarga un modelo. Abre SurfMind en el próximo artículo que ibas a leer de todas formas. Verás cómo cambia la experiencia.
Y si lo pruebas, cuéntanos para qué terminas usándolo. Los casos de uso que la gente encuentra siempre son más creativos de lo que esperaríamos.
Tu modelo de IA local está funcionando. Ahora ponlo a trabajar en cada página que navegas.
Publicaciones recientes
Ver todo
La Guía Prioritaria de Privacidad para Usar Extensiones de IA en Tu Navegador
¿Cómo usar extensiones de IA en el navegador sin sacrificar tu privacidad? Descubre BYOK, almacenamiento local y controles granulares que protegen tus datos.

Cómo exportar chats de IA a Obsidian
Aprende a exportar mensajes seleccionados de chat con IA a Obsidian con SurfMind y guarda conversaciones útiles como notas Markdown organizadas en tu vault.
Cómo exportar chats de IA a Notion
Aprende a exportar mensajes seleccionados de chats de IA a Notion con SurfMind y convertir conversaciones útiles en conocimiento organizado.