Comment Utiliser Ollama pour Converser avec N'importe Quelle Page Web

Vous avez probablement remarqué le changement en cours. ChatGPT est partout, mais l'inquiétude autour de lui grandit aussi. Que deviennent les documents que vous collez ? Qui lit vos requêtes ? Votre employeur ou vos clients peuvent-ils savoir quand vous l’utilisez ?
Ce sont des questions légitimes. Et un nombre croissant de personnes ont simplement cessé de se les poser, car elles ont installé leur IA localement.
C’est justement de cela que parle cet article. Nous allons découvrir Ollama, ce que c’est, comment le configurer, quels modèles valent la peine d’être utilisés, puis entrer dans la partie vraiment excitante : utiliser l’IA directement dans votre navigateur pour interagir avec n’importe quelle page web que vous lisez. Sans abonnement. Aucune donnée ne quitte votre machine à moins que vous ne le souhaitiez.
Que vous soyez développeur, chercheur, journaliste, ou simplement curieux à propos de l’IA et peu enclin à ce que chaque requête soit enregistrée quelque part, ceci est pour vous.
Première chose à savoir – qu’est-ce qu’Ollama ?
Ollama est un outil gratuit et open source qui vous permet de télécharger et d’exécuter des modèles de langage de grande taille directement sur votre propre ordinateur. Mac, Windows, Linux, cela fonctionne sur tous.
Considérez-le comme un gestionnaire de modèles. Vous choisissez un modèle, le téléchargez une fois, et il fonctionne entièrement sur votre matériel à partir de ce moment. Pas besoin de connexion internet. Pas de coûts d’utilisation. Aucun serveur tiers ne traite vos requêtes.
Au moment du lancement de ChatGPT, les modèles d’IA puissants n’étaient accessibles que via des services cloud. Aujourd’hui, vous pouvez faire tourner des modèles comparables en local, de façon privée, ou, si vous avez besoin de plus de puissance, utiliser le cloud d’Ollama sans changer d’outil ni de méthode. Nous y reviendrons.
L’avantage pratique est plus grand qu’il n’y paraît. Vous pouvez fournir à Ollama des documents sensibles, des notes privées, des pages web confidentielles, et selon le mode utilisé, rien de tout cela n’a besoin de sortir de votre machine. Cela signifie aussi que vous n’avez pas de frais liés au nombre de tokens consommés, qui peuvent s’accumuler en un coût mensuel réel.
À quoi les gens utilisent-ils réellement Ollama ?
Avant de voir l’installation, il vaut la peine de commencer par des cas d’usage concrets, car “faire tourner l’IA localement” peut paraître abstrait.
Les utilisateurs emploient les modèles locaux pour une variété étonnamment large de tâches : résumer de longs rapports, rédiger des emails, déboguer du code, faire des recherches sans que leurs requêtes soient stockées, analyser des contrats, traiter des notes de réunion. Les développeurs s’en servent pour tester le comportement des modèles dans un environnement contrôlé. Les écrivains pour avoir des retours sur des brouillons sans craindre que leur travail soit utilisé comme données d’entraînement. Les étudiants pour approfondir des sujets complexes sans épuiser un abonnement.
Ce qui rassemble ces usages, c’est le contrôle. Ceux qui utilisent Ollama veulent travailler avec l’IA selon leurs propres règles, pas à travers un portail par abonnement qui peut changer les tarifs, limiter le rythme, ou enregistrer leurs sessions.
Installer Ollama
Ce dont vous avez besoin
Vous n’avez pas besoin d’un ordinateur dernière génération, mais la mémoire vive compte. Nous recommandons au moins 16 Go pour une expérience fluide avec la plupart des modèles. 8 Go fonctionneront techniquement, mais vous serez limité aux plus petits modèles et les temps de réponse peuvent être lents. Si vous avez un Mac avec Apple Silicon, vous êtes dans une bonne position, car l’architecture mémoire unifiée gère très efficacement l’IA locale. Windows et Linux fonctionnent aussi très bien.
Installation
Ollama supporte les principales plateformes (macOS, Linux, Windows). La manière la plus simple d’installer :
# On macOS or Linux
curl -fsSL https://ollama.com/install.sh | sh
# Or use Homebrew on macOS
brew install ollama
# On Windows, download the installer from Ollama’s website https://ollama.com/download/windowsUne fois installé, Ollama lance un serveur local en arrière-plan sur le port 11434. Vous pouvez vérifier que tout marche en ouvrant un navigateur et en visitant http://localhost:11434, un message de confirmation doit s’afficher.
Télécharger votre premier modèle
Ouvrez un terminal et tapez :
ollama pull llama3.2Cela télécharge le modèle Llama 3.2 de Meta sur votre machine (~2 Go). La commande run gère également le téléchargement automatiquement si vous passez directement à :
ollama run llama3.2Posez votre question. Obtenez une réponse. Vous faites maintenant tourner un modèle de langage performant, entièrement sur votre propre matériel.
Quel modèle choisir ?
La bibliothèque Ollama compte plus de 100 modèles, ce qui peut sembler intimidant. Voici un point de départ pratique :
| Modèle | Adapté pour | RAM nécessaire |
|---|---|---|
gemma3:2b |
Machines plus anciennes ou bas de gamme | ~4 Go |
llama3.2 |
Usage général quotidien | ~8 Go |
mistral |
Vitesse et tâches de codage | ~8 Go |
deepseek-r1 |
Analyse, raisonnement, recherche | ~8 Go |
llama3.3:70b |
Capacité locale maximale | ~32 Go+ |
Si vous commencez, llama3.2 est un bon choix. Rapide, polyvalent, il fonctionne confortablement sur la plupart des ordinateurs portables modernes.
Vous pouvez vérifier la liste des modèles installés avec cette commande :
ollama listÀ savoir : ces modèles ont une date de coupure de connaissances et n’ont pas accès à des informations en temps réel. Pour du contenu actuel, comme une page web que vous lisez, il faut leur fournir le contexte directement. C’est exactement ce que nous allons voir.
Et si vous avez besoin d’un modèle plus puissant ?
Les modèles locaux sont impressionnants mais limités par le matériel. Un modèle à 70 milliards de paramètres exige une grande quantité de RAM. Un modèle à 671 milliards ne fonctionnera tout simplement pas sur un ordinateur personnel.
C’est pour cela que les modèles cloud d’Ollama existent. Lancés fin 2025, ils vous permettent d’exécuter des modèles massifs sur un matériel de datacenter avec la même interface Ollama que vous connaissez déjà. Même commandes, même API, même outils.
ollama run deepseek-v3.1:671b-cloudLes modèles cloud disponibles incluent :
deepseek-v3.1:671b-cloud: un des modèles open-weight les plus performants disponiblesqwen3-coder:480b-cloud: conçu spécialement pour le codegpt-oss:120b-cloudetgpt-oss:20b-cloud: modèles open-weight de OpenAI
Les modèles cloud se comportent exactement comme les modèles locaux. La seule différence est qu’ils nécessitent une connexion à ollama.com :
ollama signinEt chose importante : le cloud Ollama ne conserve pas vos données. Vous bénéficiez donc de la puissance des grands modèles cloud sans le compromis habituel sur la vie privée.
Cela signifie en pratique : utilisez les modèles locaux pour le travail sensible où rien ne doit quitter votre machine. Passez aux modèles cloud quand vous avez besoin de puissance maximale. Ollama gère les deux parfaitement, vous n’avez qu’à choisir le tag se terminant par -cloud.
La partie qui change vraiment la façon de travailler : discuter avec les pages web
Voici où les choses deviennent intéressantes.
Ollama seul est utile. Mais le connecter à votre navigateur pour pouvoir lui demander des questions sur n'importe quelle page web affichée rend le flux de travail bien plus fluide, passant d’une « expérience sympa » à un outil que vous utiliserez au quotidien.
Imaginez ce que cela permet :
- Vous lisez un article de recherche dense ? Demandez au modèle de résumer la méthodologie, d’expliquer les résultats en langage clair, ou de signaler tout ce qui semble douteux.
- Vous consultez la page tarifaire d’un concurrent ? Demandez quels sont les éléments différenciateurs, ou ce qui manque manifestement.
- Vous lisez un long article d’actualité ? Obtenez les principales affirmations, vérifiez si le titre correspond au contenu, écoutez l’argument contraire.
- Vous regardez une offre d’emploi ? Demandez si votre expérience correspond vraiment à ce qu’ils décrivent.
- Vous étudiez un document juridique ou des conditions générales ? Obtenez une explication en langage simple sans copier du texte sensible dans un outil cloud.
Tout cela selon vos propres règles. Le contenu de la page est envoyé au modèle que vous avez choisi.
Comment faire avec SurfMind
SurfMind est une extension de navigateur conçue pour ça. Elle lit le contenu de la page que vous visitez et vous permet d’avoir une vraie conversation dessus, directement dans votre navigateur, sans copier-coller.
Elle supporte les modèles locaux Ollama par défaut, ainsi que les modèles cloud Ollama, et vous offre un assistant IA performant qui fonctionne sur tout le web, selon vos conditions.
Voici comment les connecter :
Étape 1. Avant de lancer Ollama, activez l’accès navigateur avec cette commande à effectuer une fois :
# Mac/Linux
OLLAMA_ORIGINS="*" ollama serve
# Windows (PowerShell)
$env:OLLAMA_ORIGINS="*"; ollama serveVous obtenez l’erreur « port 11434 déjà utilisé » ? Cela signifie que l’application Ollama tourne déjà en arrière-plan. Fermez-la d’abord : sur Mac, cherchez l’icône Ollama dans la barre des menus et cliquez sur Quitter ; sur Windows, trouvez-la dans la zone de notification. Puis lancez de nouveau la commande ci-dessus.
Étape 2. Installez SurfMind depuis le Chrome Web Store et ouvrez-le sur n’importe quelle page.
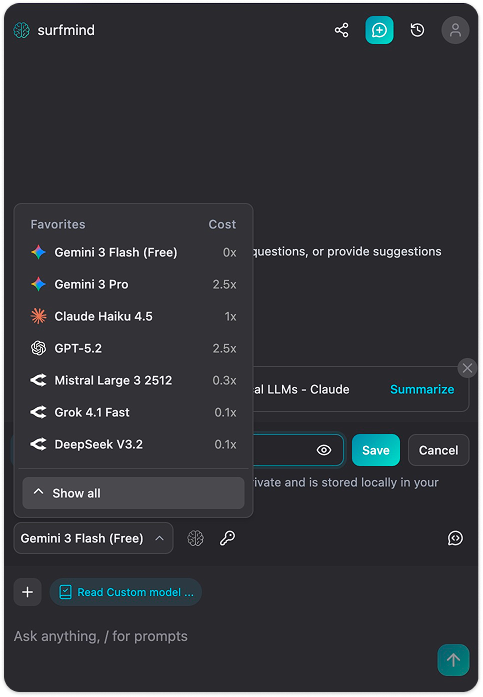
Étape 3. Cliquez sur le nom du modèle en bas du panneau SurfMind pour ouvrir vos favoris, puis passez à l’onglet Personnalisé.
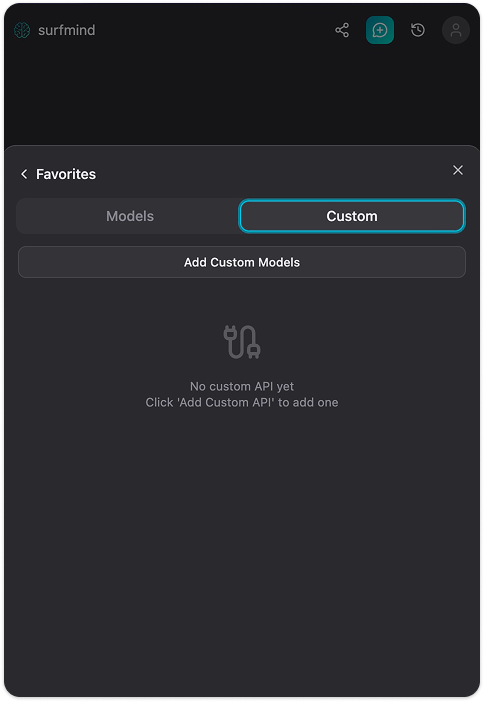
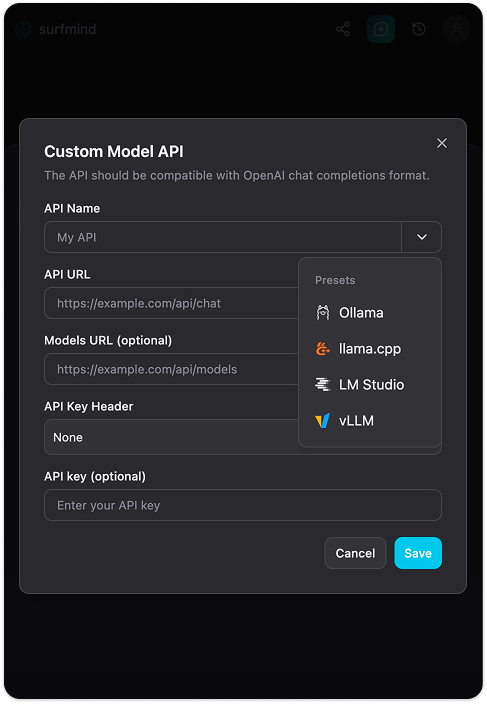
Étape 4. Cliquez sur Ajouter un modèle personnalisé. Un formulaire « API de modèle personnalisé » s’affiche. Cliquez sur la flèche déroulante près du champ Nom de l’API, vous verrez un menu Préréglages avec Ollama déjà listé. Sélectionnez Ollama et les champs se rempliront automatiquement :
- URL de l’API :
http://localhost:11434/api/chat - URL des modèles :
http://localhost:11434/api/tags - En-tête clé API : Aucun
- Clé API : (laisser vide)
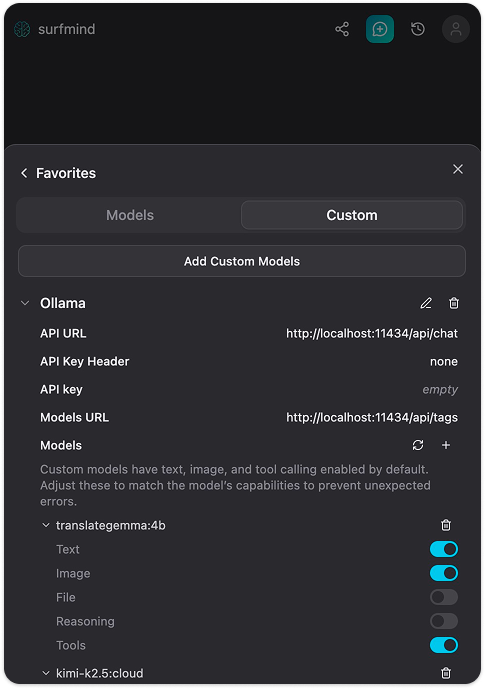
Étape 5. Cliquez sur Enregistrer. SurfMind se connectera à votre instance Ollama locale et affichera la liste des modèles installés. Ils apparaîtront dans la section Ollama, prêts à être sélectionnés.
Naviguez maintenant vers n’importe quelle page web, ouvrez SurfMind, choisissez votre modèle Ollama dans le sélecteur en bas, et commencez à poser des questions sur le contenu affiché. Voilà.
Quelques exemples pratiques à essayer
Pour chercheurs et étudiants : Ouvrez un article académique et demandez « quel est l’argument principal ici ? » ou « quelles limites les auteurs reconnaissent-ils ? » Vous vous orienterez en quelques secondes au lieu de survoler l’intégralité pour trouver la section pertinente.
Pour développeurs : Chargez de la documentation sur laquelle vous travaillez et posez des questions précises. Idéal pour naviguer dans des API ou frameworks inconnus sans casser votre flux en ouvrant une autre fenêtre de chat.
Pour usage professionnel : Analysez des rapports financiers, communiqués de presse, pages concurrentes ou analyses sectorielles. Demandez ce qui est notable, ce qui manque, ou quelles questions cela soulève. Pour une analyse approfondie, basculez sur un modèle cloud.
Pour un usage quotidien soucieux de la confidentialité : Chaque fois que vous hésitez à copier un texte dans ChatGPT à cause de son contenu, voilà une alternative.
Quelques mises en garde honnêtes
Aucun outil d’IA n’est infaillible. Les modèles produisent parfois des réponses confiantes mais erronées. C’est une limite commune à tous les modèles de langage, pas un problème spécifique au local. Pour tout ce qui nécessite une grande précision, comme l’analyse juridique, médicale ou financière, considérez les résultats comme une base à vérifier, pas une réponse finale.
Cela dit, la qualité a beaucoup progressé. Les petits modèles locaux gèrent bien la plupart des tâches quotidiennes, et si vous avez besoin de plus de puissance, les modèles cloud Ollama réduisent grandement l’écart.
À essayer, ne serait-ce qu’une fois
L’écosystème de l’IA locale a mûri plus vite qu’on ne le croit. Il y a un an, cela demandait des efforts techniques importants. Aujourd’hui, deux commandes dans un terminal et une extension de navigateur suffisent pour avoir un assistant IA performant qui fonctionne de façon privée sur n’importe quelle page web, gratuitement, et selon vos conditions.
Si vous avez été curieux d’installer votre propre IA mais pensé que c’était trop compliqué, Ollama simplifie grandement les choses. Installez-le cet après-midi. Téléchargez un modèle. Ouvrez SurfMind sur l’article que vous alliez lire de toute façon. Voyez comment cela change l’expérience.
Et si vous essayez, dites-nous pour quoi vous l’utilisez au final. Les cas d’usage découverts par chacun sont toujours plus créatifs que ce qu’on pourrait prévoir.
Votre modèle IA local tourne. Mettez-le maintenant au travail sur chaque page que vous visitez.
Articles récents
Voir tout
Le Guide Prioritaire à la Confidentialité pour Utiliser des Extensions IA dans Votre Navigateur
Comment utiliser des extensions IA pour navigateur sans sacrifier votre vie privée ? Découvrez BYOK, le stockage local et les contrôles granulaires qui protègent vos données.

Comment exporter des chats IA vers Obsidian
Apprenez à exporter des messages de chat IA sélectionnés vers Obsidian avec SurfMind et sauvegardez des conversations utiles sous forme de notes Markdown organisées dans votre vault.
Comment exporter des chats IA vers Notion
Découvrez comment exporter des messages sélectionnés de chats IA vers Notion avec SurfMind et transformer des conversations utiles en connaissances organisées.