Come Usare Ollama per Chatta con Qualsiasi Pagina Web

Probabilmente avrai notato il cambiamento in atto. ChatGPT è ovunque, ma lo è anche il crescente disagio che lo circonda. Cosa succede ai documenti che incolli? Chi legge i tuoi prompt? Il tuo datore di lavoro o i clienti possono capire se lo stai usando?
Sono domande legittime. E c’è un numero crescente di persone che ha smesso silenziosamente di farsele perché hanno spostato la loro configurazione IA in locale.
Di questo si parla in questo post. Vedremo Ollama, cos’è, come configurarlo, quali modelli vale la pena usare e poi entreremo nella parte davvero entusiasmante: utilizzare l’IA direttamente nel browser per interagire con qualsiasi pagina web che stai leggendo. Niente abbonamenti. Nessun dato lascia la tua macchina a meno che tu non voglia.
Che tu sia uno sviluppatore, un ricercatore, un giornalista o semplicemente qualcuno curioso dell’IA a cui non piace l’idea che ogni domanda venga registrata da qualche parte, questo è per te.
Prima di tutto – cos’è Ollama?
Ollama è uno strumento gratuito e open-source che ti permette di scaricare ed eseguire grandi modelli linguistici direttamente sul tuo computer. Mac, Windows, Linux: funziona su tutti.
Pensalo come un gestore di modelli. Scegli un modello, lo scarichi una volta e da quel momento gira interamente sul tuo hardware. Nessuna connessione internet richiesta. Nessun costo d’uso. Nessun server di terze parti che processa le tue richieste.
Quando ChatGPT è stato lanciato per la prima volta, i modelli IA potenti erano accessibili solo tramite servizi cloud. Ora puoi eseguire modelli comparabili completamente in locale e in modo privato, oppure, se ti serve più potenza, usare il cloud di Ollama senza cambiare strumenti o flusso di lavoro. Ne parliamo tra poco.
Il vantaggio pratico è più grande di quanto sembri. Puoi fornire a Ollama documenti sensibili, note private, pagine web riservate e, a seconda della modalità che usi, nulla di tutto ciò deve viaggiare altrove. Significa anche che non paghi costi per token che silenziosamente si accumulano fino a diventare un costo mensile reale.
A cosa serve effettivamente Ollama?
Prima di entrare nella configurazione, vale la pena radicare questo in casi d’uso reali, perché “eseguire IA localmente” può sembrare astratto.
Le persone usano modelli locali per una gamma sorprendentemente ampia di compiti: riassumere lunghi report, scrivere email, fare debug del codice, fare ricerche senza voler salvare le query, analizzare contratti, elaborare appunti di riunioni. Gli sviluppatori lo usano per testare il comportamento del modello in un ambiente controllato. Gli scrittori per ottenere feedback sulle bozze senza preoccuparsi che il loro lavoro venga usato per l’addestramento. Gli studenti per affrontare argomenti complessi senza consumare un abbonamento.
Il filo comune è il controllo. Le persone che usano Ollama vogliono lavorare con l’IA secondo le proprie condizioni, non tramite un portale in abbonamento che può cambiare prezzo, limitare le richieste o registrare le sessioni.
Configurare Ollama
Cosa ti serve
Non serve una macchina all’avanguardia, ma la RAM conta. Consigliamo almeno 16GB per un’esperienza fluida con la maggior parte dei modelli. 8GB funziona tecnicamente, ma sei limitato ai modelli più piccoli e i tempi di risposta possono sembrare lenti. Se hai un Mac con Apple Silicon sei in una posizione particolarmente buona, dato che l’architettura della memoria unificata gestisce l’IA locale molto efficientemente. Windows e Linux funzionano altrettanto bene.
Installalo
Ollama supporta le principali piattaforme (macOS, Linux, Windows). Il modo più semplice per installare:
# On macOS or Linux
curl -fsSL https://ollama.com/install.sh | sh
# Or use Homebrew on macOS
brew install ollama
# On Windows, download the installer from Ollama’s website https://ollama.com/download/windowsUna volta installato, Ollama esegue un server locale in background sulla porta 11434. Puoi verificarne il funzionamento aprendo un browser e visitando http://localhost:11434, dovresti vedere un messaggio di conferma.
Scarica il tuo primo modello
Apri un terminale e esegui:
ollama pull llama3.2Questo scarica il modello Llama 3.2 di Meta sul tuo computer (~2GB). Il comando run gestisce anche il download automaticamente se salti direttamente a:
ollama run llama3.2Digita la tua domanda. Ricevi una risposta. Stai ora eseguendo un modello linguistico capace, completamente sul tuo hardware.
Quale modello dovresti usare?
La libreria di Ollama ha oltre 100 modelli, può sembrare opprimente all’inizio. Ecco un punto di partenza pratico:
| Modello | Indicato per | RAM necessaria |
|---|---|---|
gemma3:2b |
Macchine più vecchie o meno potenti | ~4GB |
llama3.2 |
Uso generale quotidiano | ~8GB |
mistral |
Velocità e compiti di coding | ~8GB |
deepseek-r1 |
Analisi, ragionamento, ricerca | ~8GB |
llama3.3:70b |
Massima capacità locale | ~32GB+ |
Se stai iniziando, llama3.2 è la scelta giusta. È veloce, ben bilanciato e gira comodamente sulla maggior parte dei portatili moderni.
Puoi controllare la lista dei modelli installati usando questo comando:
ollama listUna cosa da sapere: questi modelli hanno una data di cutoff della conoscenza e non hanno accesso a informazioni in tempo reale. Per contenuti in tempo reale, come una pagina web che stai leggendo, devi fornire il contesto direttamente. E questo è esattamente l’obiettivo che stiamo costruendo.
E se avessi bisogno di un modello più grande e potente?
I modelli locali sono impressionanti, ma limitati dall’hardware. Un modello da 70 miliardi di parametri richiede molta RAM. Un modello da 671 miliardi semplicemente non gira su un computer personale.
Qui entrano in gioco i modelli cloud di Ollama. Rilasciati alla fine del 2025, ti permettono di far girare modelli enormi su hardware datacenter-grade usando la stessa interfaccia Ollama che già conosci. Stessi comandi, stessa API, stessi strumenti.
ollama run deepseek-v3.1:671b-cloudI modelli cloud disponibili includono:
deepseek-v3.1:671b-cloud: uno dei modelli open-weight più potenti disponibiliqwen3-coder:480b-cloud: progettato per compiti di codinggpt-oss:120b-cloudegpt-oss:20b-cloud: i modelli open-weight di OpenAI
I modelli cloud si comportano esattamente come quelli locali. L’unica differenza è che richiedono di effettuare il login su ollama.com prima:
ollama signinE cosa importante: il cloud di Ollama non conserva i tuoi dati. Quindi ottieni la potenza dei modelli cloud senza il comune compromesso sulla privacy.
Il vantaggio pratico: usa i modelli locali per lavori sensibili dove nulla deve lasciare la tua macchina. Passa ai modelli cloud quando ti serve la massima potenza. Ollama gestisce entrambi senza soluzione di continuità, ti basta scegliere il tag modello che termina con -cloud.
La parte che cambia davvero il modo in cui lavori: chattare con le pagine web
Qui le cose si fanno interessanti.
Ollama da solo è utile. Ma collegarlo al browser, così puoi indicargli qualsiasi pagina web e fare domande su cosa c’è sullo schermo, è dove il flusso di lavoro passa da “esperimento interessante” a qualcosa che userai davvero ogni giorno.
Pensa a cosa sblocca:
- Stai leggendo un articolo di ricerca complesso? Chiedi al modello di riassumere la metodologia, spiegare i risultati in parole semplici, o segnalare qualcosa che sembra forzato.
- Stai rivedendo la pagina prezzi di un concorrente? Chiedi quali sono i differenziatori o cosa manca in modo evidente.
- Stai leggendo un lungo articolo di attualità? Ottieni i punti chiave, verifica se il titolo corrisponde al contenuto, ascolta il contro-argomento.
- Guardi un annuncio di lavoro? Chiedi se la tua esperienza corrisponde davvero a quanto descritto.
- Stai studiando un documento legale o termini di servizio? Ottieni una spiegazione in linguaggio semplice senza incollare testi sensibili in uno strumento cloud.
Tutto secondo le tue condizioni. Il contenuto della pagina va al modello che hai scelto.
Come farlo con SurfMind
SurfMind è un’estensione per browser creata proprio per questo. Legge il contenuto di qualunque pagina tu stia visitando e ti permette di avere una vera conversazione a riguardo direttamente nel browser, senza copiare e incollare nulla.
Supporta i modelli locali Ollama di default, così come i modelli cloud di Ollama e ti dà un assistente IA capace che funziona su tutto il web secondo le tue condizioni.
Ecco come collegarli:
Passo 1. Prima di avviare Ollama, abilita l’accesso dal browser con questo comando una tantum:
# Mac/Linux
OLLAMA_ORIGINS="*" ollama serve
# Windows (PowerShell)
$env:OLLAMA_ORIGINS="*"; ollama serveRicevi l’errore "porta 11434 già in uso"? Significa che l’app Ollama è già in esecuzione in background. Chiudila prima su Mac, cerca l’icona Ollama nella barra dei menu e seleziona Esci; su Windows, cercala nell’area notifiche. Poi esegui di nuovo il comando sopra.
Passo 2. Installa SurfMind dal Chrome Web Store e aprilo su qualunque pagina.
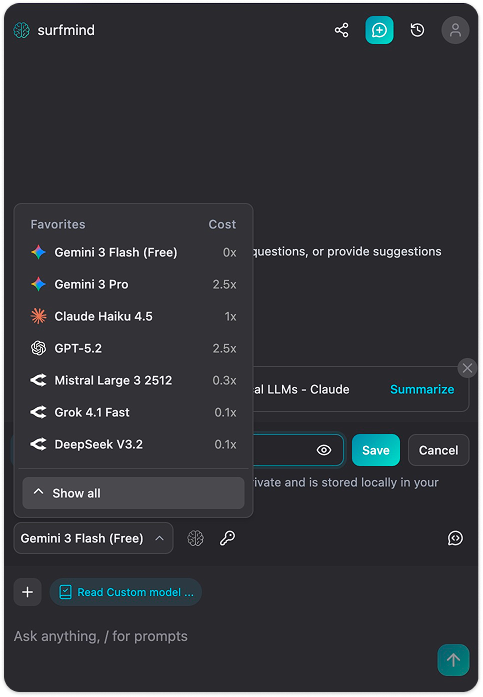
Passo 3. Clicca il nome del modello in basso nel pannello SurfMind per aprire i Preferiti, poi passa alla scheda Custom.
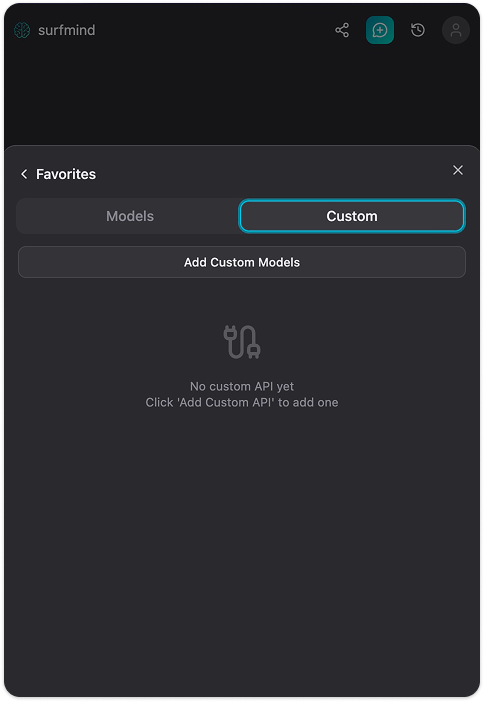
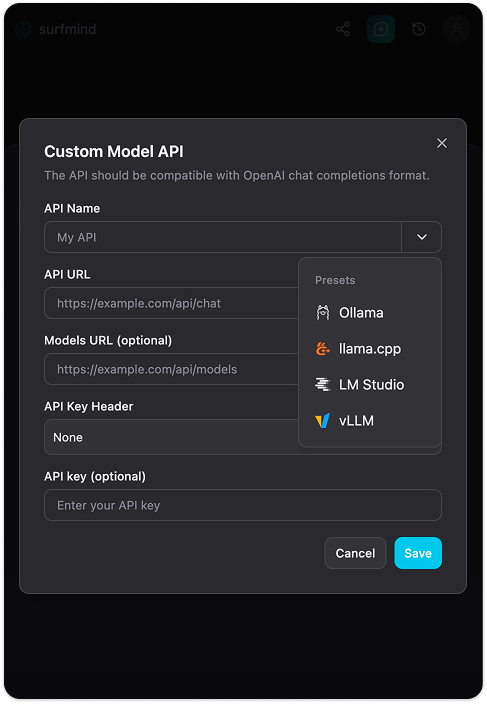
Passo 4. Clicca su Add Custom Models. Apparirà un modulo "Custom Model API". Clicca sulla freccia del menu a tendina vicino al campo Nome API, vedrai un menu Presets con già Ollama elencato. Seleziona Ollama e compilerà automaticamente tutti i campi:
- API URL:
http://localhost:11434/api/chat - Models URL:
http://localhost:11434/api/tags - API Key Header: Nessuno
- API Key: (lascia vuoto)
Passo 5. Premi Save. SurfMind si connetterà alla tua istanza locale di Ollama e scaricherà la lista dei modelli installati. Appariranno sotto la sezione Ollama, pronti per essere selezionati.
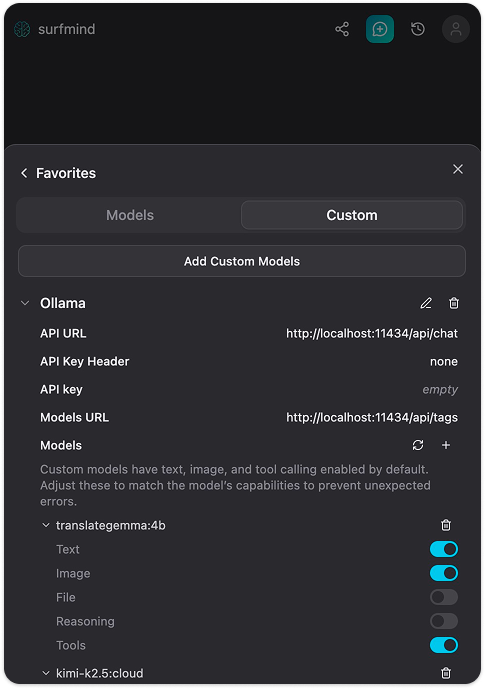
Ora naviga su qualsiasi pagina web, apri SurfMind, scegli il modello Ollama dal selettore in basso e inizia a fare domande su cosa c’è nella pagina. È tutto.
Alcuni esempi pratici da provare
Per ricercatori e studenti: Apri qualunque articolo accademico e chiedi “qual è l’argomento principale qui?” o “quali limiti riconoscono gli autori?” Ti orienterai in pochi secondi invece di scorrere l’intero pezzo per trovare la sezione rilevante.
Per sviluppatori: Apri la documentazione su cui stai lavorando e poni domande specifiche. Ottimo per navigare API o framework non familiari senza interrompere il flusso per aprire una finestra di chat separata.
Per uso aziendale: Punta su report sugli utili, comunicati stampa, pagine dei concorrenti o analisi di settore. Chiedi cosa c’è di rilevante, cosa manca o quali domande solleva. Per analisi approfondite, passa a un modello cloud per maggiore profondità.
Per uso quotidiano attento alla privacy: Ogni volta che normalmente incolleresti qualcosa in ChatGPT ma esiti per il contenuto sensibile, questa è l’alternativa.
Alcune oneste avvertenze
Nessuno strumento IA è infallibile. I modelli a volte producono risposte sicure che sono sbagliate. Questo è un limite di tutti i modelli linguistici, non un problema specifico locale. Per tutto ciò dove la precisione conta, come analisi legale, domande mediche, decisioni finanziarie, considera il risultato come un punto di partenza da verificare, non una risposta finale.
Detto questo, la qualità è molto migliorata. I modelli locali più piccoli gestiscono bene la maggior parte dei compiti quotidiani, e se ti serve più potenza, i modelli cloud di Ollama colmano notevolmente il divario.
Vale la pena provare, anche una sola volta
Lo spazio dell’IA locale è maturato più rapidamente di quanto la maggior parte delle persone pensi. Un anno fa questo richiedeva un impegno tecnico significativo. Oggi sei a due comandi da terminale e un’estensione browser da un assistente IA capace che funziona su qualunque pagina web in modo privato, gratuito e completamente secondo le tue condizioni.
Se sei stato curioso di avere il tuo setup IA ma pensavi fosse troppo complicato, Ollama lo rende accessibile. Installalo questo pomeriggio. Scarica un modello. Apri SurfMind sull’articolo che stavi per leggere comunque. Vedi come cambia l’esperienza.
E se lo provi, facci sapere a cosa lo usi. I casi d’uso che le persone scoprono sono sempre più creativi di quanto potremmo anticipare.
Il tuo modello IA locale è in funzione. Ora mettilo al lavoro su ogni pagina che navighi.
Post recenti
Vedi tutto
La guida Privacy-First all'uso delle estensioni IA nel tuo browser
Come usare estensioni IA nel browser senza sacrificare la tua privacy? Scopri BYOK, archiviazione locale e controlli granulari che proteggono i tuoi dati.

Come esportare le chat AI su Obsidian
Scopri come esportare messaggi selezionati delle chat AI su Obsidian con SurfMind e salvare conversazioni utili come note Markdown organizzate nel tuo vault.
Come esportare chat AI in Notion
Scopri come esportare messaggi selezionati dalle chat AI in Notion con SurfMind e trasformare conversazioni utili in conoscenza organizzata.