SurfMind로 로컬 LLM 또는 커스텀 AI를 브라우저에 연결하기
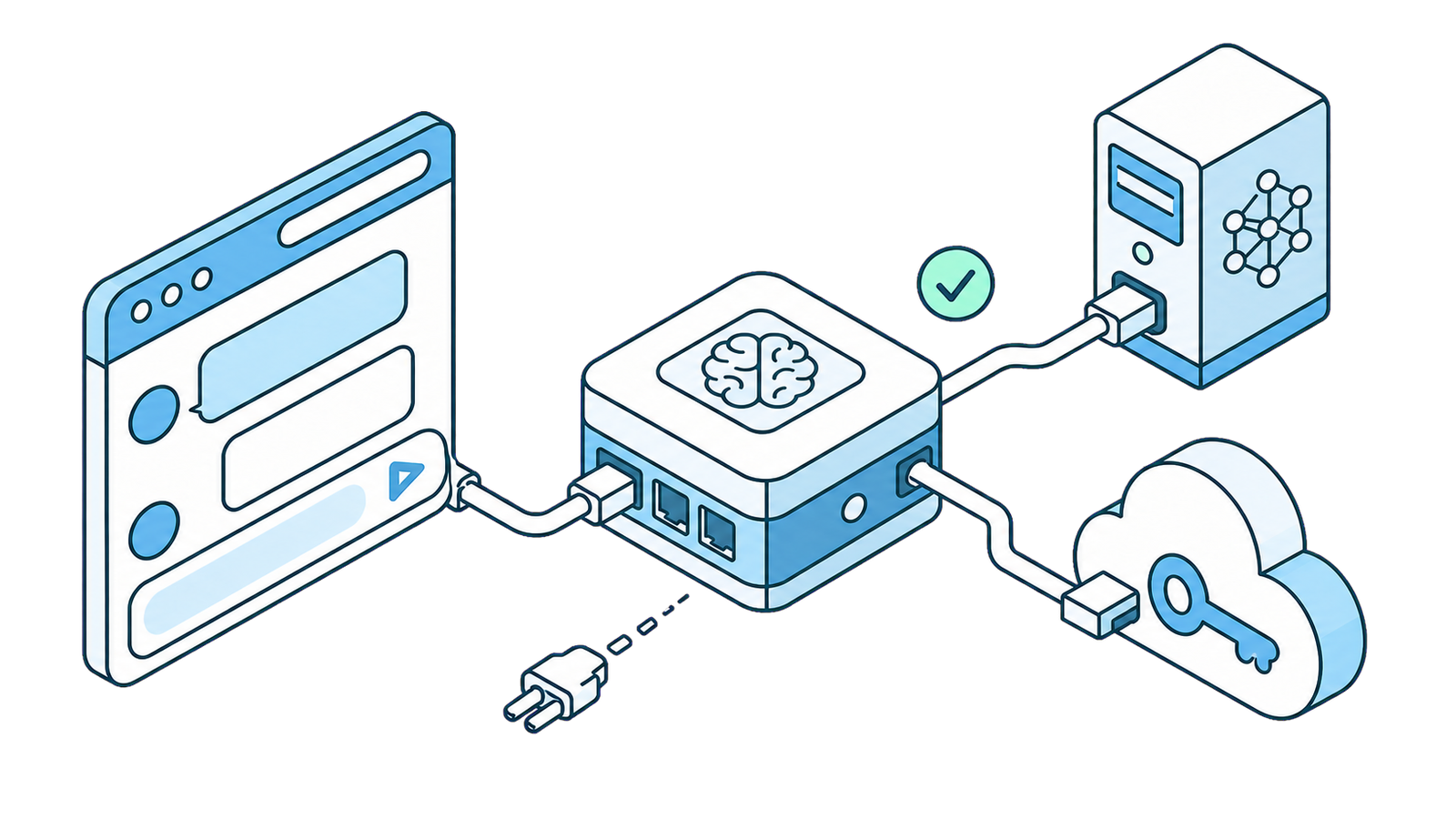
SurfMind는 특정 모델 세트에 여러분을 가두지 않습니다. Custom Model API(커스텀 모델 API)를 통해, 내 컴퓨터에서 돌아가는 모델(Ollama, LM Studio, Jan, llama.cpp, vLLM)은 물론, OpenAI completion API를 따르는 거의 모든 외부 AI 제공자 — Poe, z.ai, Together, Groq, DeepSeek, AWS Bedrock 등 수십 종 — 를 연결할 수 있습니다.
문제는 이것입니다. 첫 시도에 작동하지 않는다면, 사소한 설정 실수 때문일 가능성이 높습니다. 그런데 돌아오는 오류("connection failed", "401", "404", "model not found")만으로는 원인을 파악하기가 까다롭습니다.
이 글은 빠른 점검과 자가 해결 가이드입니다. 체크리스트를 훑어보며 설정을 확인하세요. 그래도 안 된다면 wave@surfmind.ai 로 이메일을 보내주세요.
특정 제공자를 찾고 계신가요? 목록을 확인하세요: 로컬 모델(Ollama, LM Studio, Jan…) 또는 AI 제공자(Poe, z.ai, Together, Groq, AWS…).
60초 체크리스트
다른 무엇보다 먼저, 아래 항목들을 확인해 보세요. 대부분의 설정 문제는 이 중 하나로 귀결됩니다:
- 서버가 실제로 실행 중인가요? 로컬 모델의 경우, 러너(Ollama, LM Studio 등)가 시작되어 있어야 하며 그리고 모델이 로드되어 있어야 합니다.
- 포트가 맞나요? Ollama는
11434입니다. LM Studio는1234입니다. 이 둘은 서로 바꿔 쓸 수 없으며, 가장 흔한 실수가 바로 이것입니다. - 경로가 맞나요? Ollama의 네이티브 경로는
/api/chat입니다. 그 외 거의 모든 것은/v1/chat/completions입니다. 둘을 헷갈리면 오류가 납니다. - 베이스 URL만 붙여넣은 게 아니라 전체 엔드포인트를 붙여넣었나요? SurfMind의 API URL 필드는
/chat/completions(Ollama는/api/chat)로 끝나는 완전한 URL을 원합니다.https://api.provider.com/v1만 있으면 안 됩니다. - API 키(그리고 그 헤더)가 올바른가요? 로컬 러너는 보통 키가 필요 없습니다. 외부 제공자는 헤더로
Authorization을, 값으로는 실제 키를 필요로 합니다. - 브라우저에서 로컬 모델을 쓸 때: CORS가 허용되었나요? 이것은 로컬 설정에만 필요한 추가 단계입니다(
OLLAMA_ORIGINS, 또는 LM Studio의 "Enable CORS").
그래도 막혔다면 계속 읽어보세요 — 위 항목 각각에는 사람들이 자주 걸려 넘어지는 미묘한 변형이 있습니다.
각 필드에 무엇을 넣어야 하나
Custom 탭 → Add Custom Models를 열면 "Custom Model API" 양식이 나타납니다. 각 필드가 정확히 무엇을 원하는지 정리했습니다:
| 필드 | 입력할 내용 |
|---|---|
| API Name | 원하는 이름을 자유롭게 붙이면 됩니다(예: "Groq" 또는 "My Ollama"). 드롭다운 화살표를 클릭하면 프리셋을 불러올 수 있습니다 — Ollama와 범용 OpenAI 호환 옵션이 나머지를 자동으로 채워줍니다. |
| API URL | 베이스 URL이 아닌 전체 chat 엔드포인트입니다. Ollama의 경우 http://localhost:11434/api/chat이고, 그 외 모두는 /chat/completions로 끝납니다. 실수 #1을 참고하세요. |
| Models URL (선택) | 사용 가능한 모델 목록을 반환하는 엔드포인트입니다. 이 값을 넣어두면 모델 이름을 일일이 입력하지 않고 SurfMind가 드롭다운으로 보여줍니다. Ollama: /api/tags. OpenAI 호환: /v1/models. 제공자에 목록 엔드포인트가 없으면 비워두세요 — 그러면 모델 id를 직접 입력하면 됩니다. |
| API Key Header | 키가 전송되는 방식입니다. None = 인증 없음(로컬 모델). Authorization = Authorization: Bearer <key>로, 거의 모든 클라우드 제공자가 사용합니다. x-api-key = x-api-key: <key>로, Anthropic 스타일 API와 일부 제공자가 사용합니다. |
| API Key (선택) | 키 그 자체일 뿐, 그 이상은 없습니다. Bearer라는 단어는 입력하지 마세요. SurfMind가 알아서 추가합니다. 로컬 모델은 비워두세요. |
사람들이 가장 자주 틀리는 두 필드는 API URL(베이스 vs 전체 엔드포인트)과 API Key Header(어떤 헤더인가)입니다. 이 가이드의 나머지는 바로 이 둘을 파고듭니다.
실수 #1: API URL 경로 (/api/chat vs /v1/chat/completions 함정)
이것이 가장 큰 문제이며, 왜 일어나는지 이해할 가치가 있습니다.
이 세계에는 서로 다른 두 가지 API "방언"이 있습니다:
- Ollama의 네이티브 API, 이는
http://localhost:11434/api/chat를 사용합니다. - OpenAI completion API, 이는
.../v1/chat/completions를 사용합니다. LM Studio, vLLM, Jan, Poe, z.ai, Together, Groq 등 사실상 나머지 전부가 따르는 방식입니다.
그래서 LM Studio용으로 작성된 설정 가이드를 복사해 그 경로를 Ollama에 쓰면(또는 그 반대), 서버가 멀쩡히 돌아가고 있는데도 404가 납니다. 서버는 켜져 있고, 단지 엉뚱한 문을 두드리고 있을 뿐입니다.
| 러너 / 제공자 | 올바른 API URL |
|---|---|
| Ollama (네이티브) | http://localhost:11434/api/chat |
| Ollama (OpenAI 호환 모드) | http://localhost:11434/v1/chat/completions |
| LM Studio | http://localhost:1234/v1/chat/completions |
| 모든 OpenAI 호환 | https://<host>/v1/chat/completions |
알아두면 좋은 점: Ollama는 사실 두 방언을 모두 지원합니다. SurfMind의 Ollama preset은 네이티브
/api/chat경로를 사용하는데, 가장 간단한 경로이며 자동 모델 탐색까지 제공합니다. Ollama의/v1/chat/completions경로는 어떤 도구가 OpenAI 형식을 명시적으로 요구할 때만 필요합니다. SurfMind에서는 그냥 프리셋을 쓰세요.
실수 #2: 포트 번호
모든 로컬 러너는 각자의 기본 포트를 고르는데, 서로 비슷해 보여서 잘못 누르기 쉽습니다:
| 도구 | 기본 포트 | 전체 chat URL |
|---|---|---|
| Ollama | 11434 |
http://localhost:11434/api/chat |
| LM Studio | 1234 |
http://localhost:1234/v1/chat/completions |
| Jan | 1337 |
http://localhost:1337/v1/chat/completions |
llama.cpp (llama-server) |
8080 |
http://localhost:8080/v1/chat/completions |
| vLLM | 8000 |
http://localhost:8000/v1/chat/completions |
| LocalAI | 8080 |
http://localhost:8080/v1/chat/completions |
11434 vs 1234가 전형적인 혼동입니다 — 얼핏 보면 헷갈리기 쉽지만, 숫자 하나만 틀려도 아무것도 연결되지 않습니다. 포트를 직접 바꿨다면(예: vLLM을 --port 9000으로 실행했다면), 기본값이 아니라 직접 지정한 포트를 사용하세요.
빠른 점검: 브라우저에서 그 포트를 열어보세요. http://localhost:11434에 접속하면 Ollama의 "Ollama is running" 메시지가 보여야 합니다. 페이지가 아예 로드되지 않는다면 서버가 켜져 있지 않거나 포트가 틀린 것입니다.
실수 #3: 엔드포인트 대신 베이스 URL을 붙여넣기
제공자 문서는 거의 항상 베이스 URL을 줍니다 — https://api.poe.com/v1 같은 것 말이죠. 그들의 코드 샘플이 OpenAI SDK를 사용하고, 그 SDK가 내부에서 /chat/completions를 알아서 붙여주기 때문입니다.
SurfMind의 API URL 필드는 그렇게 해주지 않습니다. 완전한 엔드포인트를 기대합니다. 그러니 경로를 직접 추가해야 합니다:
- 문서의 베이스 URL:
https://api.poe.com/v1 - SurfMind에 붙여넣을 것:
https://api.poe.com/v1/chat/completions
Models URL 필드(사용 가능한 모델 자동 나열에 사용)도 같은 원리입니다: 베이스를 가져와 /models를 붙이세요 → https://api.poe.com/v1/models.
관련된 두 가지 실수:
/v1중복. 베이스가 이미/v1로 끝난다면 또 붙이지 마세요..../v1/v1/chat/completions는 404입니다.- 끝의 슬래시. 끝에 슬래시가 붙은
.../chat/completions/는 일부 서버에서 실패할 수 있습니다. 떼어내세요.
실수 #4: Models URL이 API URL과 일치하지 않음
Models URL은 선택 사항입니다. 제공자가 제공하는 모델 목록을 가져오기 위해 SurfMind가 호출하는 엔드포인트로, 모델 이름을 직접 입력하는 대신 드롭다운으로 보여주기 위한 것입니다. 저장한 뒤 모델이 선택 목록에 나타나지 않는다면, 보통 이 필드가 원인입니다. 이 필드는 chat 엔드포인트와 같은 방언을 따라야 합니다:
| 방언 | Models URL |
|---|---|
| Ollama (네이티브) | http://localhost:11434/api/tags |
| OpenAI 호환 (그 외 모두) | https://<host>/v1/models |
흔한 실수는 둘을 섞는 것입니다 — OpenAI 호환 제공자에 /api/tags를 쓰거나, Ollama 네이티브 프리셋에 /v1/models를 쓰는 것이죠. Ollama preset을 사용했다면 이 값이 올바르게 채워져 있으니, 그대로 두세요.
비워둘 때: 일부 제공자는 공개 모델 목록 엔드포인트를 노출하지 않거나 차단합니다. 괜찮습니다 — Models URL을 비워두고 정확한 모델 id를 모델 필드에 직접 입력하세요(실수 #7 참고). 채팅은 여전히 작동하며, 다만 자동 채워지는 드롭다운만 못 받을 뿐입니다.
실수 #5: API Key Header (Bearer vs x-api-key)
API Key Header 드롭다운은 키가 요청에 어떻게 첨부될지를 결정합니다. 잘못 고르면 완벽하게 유효한 키로도 401 Unauthorized가 납니다. 세 가지 선택지가 있습니다:
| API Key Header | SurfMind가 보내는 것 | 사용 대상 |
|---|---|---|
| None | 아무것도 없음 | 로컬 모델은 보통 인증이 필요 없지만, 실제 설정을 확인해 볼 가치가 있습니다. |
| Authorization | Authorization: Bearer <your key> |
거의 모든 클라우드 제공자: Poe, z.ai, Together, Groq, DeepSeek, Mistral, Fireworks, xAI, AWS Bedrock. OpenAI 호환 API의 기본값입니다. |
| x-api-key | x-api-key: <your key> |
Anthropic 스타일 API 및 Bearer 토큰 대신 raw 키 헤더를 기대하는 소수의 제공자. |
그다음 API Key 필드에는 키 자체만 넣습니다:
- Authorization을 선택했을 때
Bearer라는 단어를 입력하지 마세요 — SurfMind가 추가합니다. - 끝에 공백을 남기지 마세요(의외로 401의 흔한 원인입니다).
- 로컬 모델의 경우 비워두세요. (LM Studio는 예외입니다 — 비어 있지 않은 어떤 값을 원하며, 자체 문서에서는
lm-studio를 사용합니다.)
어떤 헤더를 쓰는지 확실하지 않다면: OpenAI 호환 제공자의 99%는 Authorization을 사용합니다. 제공자 문서가 명시적으로 x-api-key 헤더를 보여줄 때만 x-api-key를 쓰세요. 그래도 401이 난다면? 키를 재발급하고, 헤더 선택을 다시 확인하며, 떠도는 공백이 없는지 확인하세요.
실수 #6: CORS — 로컬 전용 함정
브라우저는 서버가 확장 프로그램으로부터의 요청을 명시적으로 허용하지 않는 한 로컬 서버 호출을 거부합니다. 이것은 특히 로컬 설정에서 걸리는 문제입니다(외부 제공자는 이미 허용하고 있습니다).
Ollama: 브라우저 접근을 활성화한 채로 시작하세요:
# Mac/Linux OLLAMA_ORIGINS="*" ollama serve # Windows (PowerShell) $env:OLLAMA_ORIGINS="*"; ollama serve"port 11434 already in use"? Ollama 백그라운드 앱이 이미 실행 중입니다. 먼저 종료한 뒤(Mac은 메뉴 바, Windows는 시스템 트레이), 위 명령을 실행하세요.
LM Studio: Developer / 로컬 서버 탭에서, 서버를 시작하기 전에 Enable CORS를 켜세요.
한 가지 더 미묘한 점: localhost가 연결되지 않으면 대신 127.0.0.1을 시도해 보세요(또는 그 반대). 일부 시스템에서는 둘이 같은 방식으로 해석되지 않습니다.
실수 #7: 모델 이름은 정확히 일치해야 함
연결된 뒤에는, 선택하는 모델 이름 이 제공자가 기대하는 것과 정확히 일치해야 합니다 — 대소문자까지 포함해서요. 모델을 자동으로 나열하지 않거나, 특이한 명명 방식을 쓰는 제공자에서 사람들이 자주 걸려 넘어집니다:
- Poe는
Claude-Sonnet-4.6이나GPT-5.4같은 표시용 봇 이름을 사용합니다 — Poe에 나타나는 그대로 정확히 복사하세요. - z.ai는
glm-4.6,glm-5같은 id를 사용합니다. - Together AI는 네임스페이스가 붙은 id를 사용합니다:
meta-llama/Llama-3.3-70B-Instruct-Turbo,deepseek-ai/DeepSeek-V3. - Fireworks는 전체 경로 id를 사용합니다:
accounts/fireworks/models/llama-v3p3-70b-instruct.
연결은 되는데 "model not found"가 뜬다면, 거의 항상 이름 오타이거나 대소문자가 틀린 것입니다. SurfMind가 Models URL을 통해 모델을 자동으로 나열할 수 있을 때는, 입력하는 대신 목록에서 고르세요.
빠른 참조: 로컬 모델
아래 항목은 모두 내 컴퓨터에서 실행됩니다. SurfMind의 Custom 탭 → Add Custom Models를 열고, 해당하는 프리셋을 고른 뒤(Ollama는 자체 프리셋이 있고, 나머지는 범용 OpenAI-compatible 프리셋을 사용), API Key Header를 None으로 설정하세요. 제공자 이름은 각 도구의 설정 문서로 연결됩니다.
- API URL:
http://localhost:11434/api/chat - Models URL:
http://localhost:11434/api/tags - API 키: 없음
- API URL:
http://localhost:1234/v1/chat/completions - Models URL:
http://localhost:1234/v1/models - API 키: 비어 있지 않은 아무 값(예:
lm-studio)
- API URL:
http://localhost:1337/v1/chat/completions - Models URL:
http://localhost:1337/v1/models - API 키: 없음(또는 발급받은 Jan 키)
- API URL:
http://localhost:8080/v1/chat/completions - Models URL:
http://localhost:8080/v1/models - API 키: 없음(
--api-key로 시작하지 않았다면)
- API URL:
http://localhost:8000/v1/chat/completions - Models URL:
http://localhost:8000/v1/models - API 키: 설정했다면 해당
--api-key값
- API URL:
http://localhost:8080/v1/chat/completions - Models URL:
http://localhost:8080/v1/models - API 키: 없음
이들 중 어떤 것이든 CORS 단계(실수 #6)를 잊지 마세요. 특히 Ollama의 경우, 스크린샷이 포함된 전체 안내는 Ollama 가이드에 있으며, 앞의 두 가지 사이에서 고민 중이라면 Ollama vs LM Studio를 참고하세요.
빠른 참조: 인기 AI 제공자
이 클라우드 제공자들은 모두 OpenAI 호환 API를 지원합니다. 범용 OpenAI-compatible 프리셋을 사용하고, API Key Header를 Authorization으로 설정한 뒤(모두 Bearer 토큰을 사용), 키를 붙여넣으세요. 제공자 이름은 각 제공자의 API 문서로 연결됩니다.
Poe — 수백 개 모델(Claude, GPT, Gemini, Llama…)을 위한 단일 키이며, Poe 구독 포인트로 과금됩니다. 모델 이름은 표시용 봇 이름이므로 Poe에 표시된 그대로 정확히 복사하세요(예: Claude-Sonnet-4.6, GPT-5.4). 키는 poe.com → Settings → API key에서 받습니다.
- API URL:
https://api.poe.com/v1/chat/completions - Models URL:
https://api.poe.com/v1/models
CanopyWave — 오픈 모델(Kimi, DeepSeek, Llama, Qwen)을 제공하는 GPU 클라우드 제공자입니다. 키는 CanopyWave 대시보드에서 받습니다.
- API URL:
https://inference.canopywave.io/v1/chat/completions - Models URL:
https://inference.canopywave.io/v1/models
z.ai (GLM) — Zhipu의 GLM 모델(glm-4.6, glm-5). 주의: z.ai는 별도의 Coding Plan 엔드포인트(https://api.z.ai/api/coding/paas/v4)와 PaaS 엔드포인트(https://api.z.ai/api/paas/v4)도 공개합니다 — 아래의 OpenAI 호환 엔드포인트를 사용하고, /v1을 추가로 붙이지 마세요.
- API URL:
https://api.z.ai/api/openai/v1/chat/completions - Models URL:
https://api.z.ai/api/openai/v1/models
Together AI — 방대한 오픈 모델 카탈로그. 모델 id가 깁니다(meta-llama/Llama-3.3-70B-Instruct-Turbo) — Together의 모델 페이지에서 그대로 정확히 복사하세요.
- API URL:
https://api.together.xyz/v1/chat/completions - Models URL:
https://api.together.xyz/v1/models
Groq — 극도로 빠른 추론. 주의: 경로가 /v1이 아니라 /openai/v1입니다.
- API URL:
https://api.groq.com/openai/v1/chat/completions - Models URL:
https://api.groq.com/openai/v1/models
DeepSeek — 현재 모델은 deepseek-v4-flash와 deepseek-v4-pro입니다(구형 deepseek-chat / deepseek-reasoner 별칭은 폐기되는 중입니다 — 최신 정보는 DeepSeek 문서를 확인하세요). /v1은 선택 사항이며, DeepSeek은 있든 없든 URL을 받아들입니다.
- API URL:
https://api.deepseek.com/v1/chat/completions - Models URL:
https://api.deepseek.com/v1/models
Mistral — mistral-large-latest, mistral-small-latest 등. 표준 OpenAI 호환입니다.
- API URL:
https://api.mistral.ai/v1/chat/completions - Models URL:
https://api.mistral.ai/v1/models
Fireworks AI — 주의: 경로가 /v1이 아니라 /inference/v1입니다. 모델 id는 accounts/fireworks/models/llama-v3p3-70b-instruct 같은 형태입니다.
- API URL:
https://api.fireworks.ai/inference/v1/chat/completions - Models URL:
https://api.fireworks.ai/inference/v1/models
xAI (Grok) — Grok 모델(grok-4 등). 표준 OpenAI 호환입니다.
- API URL:
https://api.x.ai/v1/chat/completions - Models URL:
https://api.x.ai/v1/models
AWS Bedrock — Bedrock에는 이제 OpenAI 호환 엔드포인트가 있지만, 두 가지 주의점이 있습니다: 호스트가 리전별로 다르고(예: us-west-2), 경로가 /openai/v1입니다. Bedrock API key(콘솔에서 생성하는 bearer 토큰)를 사용해야 하며 — 평소의 AWS 액세스 키/SigV4가 아닙니다. 모델 id는 openai.gpt-oss-120b-1:0 같은 형태입니다.
- API URL:
https://bedrock-runtime.<region>.amazonaws.com/openai/v1/chat/completions - Models URL: 비워두세요 — 모델 id는 나중에 입력합니다
그래도 연결되지 않나요? 마지막 점검
이 목록을 위에서부터 짚어보세요:
- 브라우저에서 API URL의 호스트를 열어보세요. 로컬 서버가 로드되지 않음 → 실행 중이 아니거나, 포트가 틀린 것입니다.
- 경로를 다시 읽으세요. Ollama →
/api/chat. 그 외 모두 →/v1/chat/completions(또는 표에 있는 제공자별 특수 경로). - 베이스가 아니라 전체 엔드포인트를 붙여넣었는지 확인하고,
/v1중복이나 끝의 슬래시가 없는지 확인하세요. - 401? 키나 헤더입니다. 헤더 =
Authorization, 공백 없는 키,Bearer접두사 없음. - 404 "model not found"? 연결은 정상입니다 — 모델 이름을 고치세요(정확한 대소문자).
- 로컬 모델인데 브라우저가 차단? CORS를 활성화하고(
OLLAMA_ORIGINS="*"또는 LM Studio의 토글),127.0.0.1과localhost를 번갈아 시도하세요.
이 순서는 대부분의 설정 문제를 해결합니다.
여전히 도움이 필요하신가요?
체크리스트를 다 거쳤는데도 제공자가 연결되지 않는다면, 시도하고 있는 제공자와 보이는 오류를 적어 wave@surfmind.ai 로 이메일을 보내주세요. 연결되도록 도와드리겠습니다.
연결되셨나요? 막 읽으려던 다음 페이지에서 SurfMind를 열고, 직접 연결한 모델을 활용해 보세요.
최근 게시물
모두 보기
Firefox에서 프라이빗 AI: 텔레메트리 제로로 로컬 모델 실행하기
로컬 모델로 작동하는 프라이빗 AI 어시스턴트를 Firefox에 추가해, 페이지 내용이 절대 머신을 떠나지 않게 하세요. 텔레메트리도, 클라우드도, 타협도 없습니다.

2026년 로컬 AI 모델을 위한 최고의 브라우저 확장 프로그램 (Ollama, LM Studio 외)
2026년 로컬 AI 모델을 실행하기 위한 최고의 브라우저 확장 프로그램들. 잘 다듬어진 로컬+클라우드 사이드바부터 오픈소스 Ollama 도구까지. 어떤 페이지와도, 개인적으로 채팅하세요.
Ollama vs LM Studio: 나에게 맞는 로컬 AI 도구는?
2026년 로컬에서 AI 모델을 실행하는 Ollama와 LM Studio를 과장 없이 실용적으로 비교하고, 둘 중 무엇으로든 어떤 웹 페이지와도 채팅하는 방법까지 알려드립니다.