Como Usar Ollama para Conversar com Qualquer Página da Web

Você provavelmente já percebeu a mudança que está acontecendo. O ChatGPT está em toda parte, mas junto vem um crescente desconforto em relação a ele. O que acontece com os documentos que você cola? Quem lê seus prompts? Seu empregador ou clientes conseguem perceber quando você o utiliza?
Essas são perguntas legítimas. E há um número crescente de pessoas que simplesmente pararam de fazê-las porque migraram seu setup de IA para local.
É sobre isso que este post vai falar. Vamos explorar o Ollama, o que é, como configurá-lo, quais modelos valem a pena usar e depois vamos para a parte que realmente empolga: usar IA diretamente no seu navegador para interagir com qualquer página web que você estiver lendo. Sem assinaturas. Nenhum dado sai da sua máquina a menos que você queira.
Seja você um desenvolvedor, pesquisador, jornalista ou apenas alguém curioso sobre IA e que não gosta da ideia de todas as consultas serem registradas em algum lugar, isto é para você.
Antes de mais nada - o que é Ollama?
Ollama é uma ferramenta gratuita e de código aberto que permite baixar e executar grandes modelos de linguagem diretamente no seu próprio computador. Mac, Windows, Linux, funciona em todos eles.
Pense nele como um gerenciador de modelos. Você escolhe um modelo, baixa uma vez, e ele roda inteiramente no seu hardware a partir daí. Sem necessidade de conexão com a internet. Sem custos de uso. Nenhum servidor de terceiros processando suas queries.
Na época em que o ChatGPT foi lançado, modelos de IA poderosos só eram acessíveis por serviços em nuvem. Agora você pode rodar modelos comparáveis completamente local e privadamente, ou, se precisar de mais potência, usar a nuvem do Ollama sem trocar de ferramenta ou mudar seu fluxo de trabalho. Falaremos mais sobre isso adiante.
A vantagem prática é maior do que parece. Você pode alimentar o Ollama com documentos sensíveis, notas privadas, páginas web confidenciais e, dependendo do modo usado, nada disso precisa sair do seu computador. Também significa que você não paga taxas por token que silenciosamente se acumulam em um custo mensal real.
Para que as pessoas realmente usam o Ollama?
Antes de falar da configuração, vale ancorar isso em casos reais, porque "rodar IA localmente" pode soar abstrato.
Pessoas usam modelos locais para uma gama surpreendentemente ampla de coisas: resumir relatórios longos, redigir e-mails, depurar código, fazer pesquisas sem querer que suas consultas sejam armazenadas, analisar contratos, processar anotações de reuniões. Desenvolvedores usam para testar o comportamento do modelo em um ambiente controlado. Escritores para obter feedback sobre rascunhos sem se preocupar que seu trabalho seja usado como dado de treinamento. Estudantes para estudar tópicos complexos sem queimar uma assinatura.
O ponto em comum é controle. Quem usa Ollama tende a querer trabalhar com a IA nos seus próprios termos, não por um portal de assinatura que pode mudar preços, limitar taxas ou registrar suas sessões.
Como configurar o Ollama
O que você vai precisar
Não precisa de uma máquina de última geração, mas a RAM é importante. Recomendamos pelo menos 16GB para uma experiência fluida com a maioria dos modelos. 8GB funcionam tecnicamente, mas você ficará limitado aos modelos menores e os tempos de resposta podem parecer lentos. Se você tem um Mac com Apple Silicon, está em uma posição especialmente boa, pois a arquitetura de memória unificada lida com IA local de forma muito eficiente. Windows e Linux funcionam muito bem também.
Instale
Ollama suporta as principais plataformas (macOS, Linux, Windows). A maneira mais fácil de instalar:
# On macOS or Linux
curl -fsSL https://ollama.com/install.sh | sh
# Or use Homebrew on macOS
brew install ollama
# On Windows, download the installer from Ollama’s website https://ollama.com/download/windowsDepois de instalado, o Ollama executa um servidor local em segundo plano na porta 11434. Você pode verificar se está funcionando abrindo um navegador e acessando http://localhost:11434, você deverá ver uma mensagem de confirmação.
Baixe seu primeiro modelo
Abra um terminal e execute:
ollama pull llama3.2Isso baixa o modelo Llama 3.2 da Meta para sua máquina (~2GB). O comando run também faz o download automaticamente se você pular direto para:
ollama run llama3.2Digite sua pergunta. Receba uma resposta. Agora você está rodando um modelo de linguagem capaz, completo no seu próprio hardware.
Qual modelo você deve usar?
A biblioteca do Ollama tem mais de 100 modelos, o que pode parecer intimidante no começo. Aqui vai um ponto de partida prático:
| Modelo | Indicado para | RAM necessária |
|---|---|---|
gemma3:2b |
Máquinas mais antigas ou com specs modestos | ~4GB |
llama3.2 |
Uso geral diário | ~8GB |
mistral |
Velocidade e tarefas de codificação | ~8GB |
deepseek-r1 |
Análise, raciocínio, pesquisa | ~8GB |
llama3.3:70b |
Capacidade máxima local | ~32GB+ |
Se está começando, llama3.2 é a escolha certa. É rápido, equilibrado e roda confortavelmente na maioria dos laptops modernos.
Você pode verificar a lista de modelos instalados com este comando:
ollama listAlgo importante de saber: esses modelos têm uma data de corte de conhecimento e não acessam informações ao vivo. Para conteúdos em tempo real, como uma página web que você está lendo, você precisará fornecer o contexto diretamente. Exatamente para isso estamos caminhando.
E se precisar de um modelo maior e mais potente?
Modelos locais impressionam, mas são limitados pelo seu hardware. Um modelo de 70B parâmetros exige muita RAM. Um de 671B simplesmente não roda em um computador pessoal.
É aqui que entram os modelos em nuvem do Ollama. Disponibilizados no final de 2025, eles permitem rodar modelos enormes em hardware de nível datacenter usando a mesma interface Ollama que você já conhece. Mesmos comandos, mesma API, mesmas ferramentas.
ollama run deepseek-v3.1:671b-cloudModelos em nuvem disponíveis incluem:
deepseek-v3.1:671b-cloud: um dos modelos open-weight mais capazes disponíveisqwen3-coder:480b-cloud: feito especialmente para tarefas de codificaçãogpt-oss:120b-cloudegpt-oss:20b-cloud: modelos OpenAI open-weight
Modelos em nuvem se comportam exatamente como os locais. A única diferença é que é necessário fazer login no ollama.com primeiro:
ollama signinE o mais importante: a nuvem Ollama não retém seus dados. Assim você obtém o poder dos grandes modelos em nuvem sem a usual troca pela privacidade.
Na prática: use modelos locais para trabalhos sensíveis onde nada deve sair da sua máquina. Troque para modelos em nuvem quando precisar da máxima capacidade. Ollama gerencia ambos sem emendas, você só escolhe a tag do modelo que termina em -cloud.
A parte que realmente muda seu jeito de trabalhar: conversar com páginas web
Aqui é que as coisas ficam interessantes.
Ollama sozinho já é útil. Mas conectá-lo ao seu navegador, para que você possa apontá-lo para qualquer página web e fazer perguntas sobre o que está na tela, é onde o fluxo muda de "experimento legal" para algo que você vai querer usar todos os dias.
Pense no que isso libera:
- Lendo um artigo de pesquisa denso? Peça para o modelo resumir a metodologia, explicar os resultados em linguagem simples ou apontar algo que pareça exagero.
- Revisando a página de preços de um concorrente? Pergunte quais são os diferenciais ou o que está conspicuamente ausente.
- Passando por um longo artigo de notícia? Obtenha as principais afirmações, verifique se a manchete condiz com o conteúdo, ouça o argumento contrário.
- Vendo uma vaga de emprego? Pergunte se sua experiência realmente corresponde ao que eles descrevem.
- Analisando um documento legal ou termos de serviço? Receba um resumo em linguagem simples sem precisar colar texto sensível em uma ferramenta na nuvem.
Tudo isso nos seus próprios termos. O conteúdo da página vai para o modelo que você escolher.
Como fazer isso com SurfMind
SurfMind é uma extensão de navegador construída exatamente para isso. Ela lê o conteúdo da página em que você está e permite ter uma conversa real sobre ela diretamente no seu navegador, sem copiar e colar nada.
Suporta modelos Ollama locais nativamente, assim como os modelos em nuvem do Ollama, e te dá um assistente de IA capaz que funciona em toda a web nos seus próprios termos.
Veja como conectá-los:
Passo 1. Antes de iniciar o Ollama, habilite o acesso via navegador com este comando único:
# Mac/Linux
OLLAMA_ORIGINS="*" ollama serve
# Windows (PowerShell)
$env:OLLAMA_ORIGINS="*"; ollama serveRecebendo erro "porta 11434 já está em uso"? Isso significa que o app Ollama já está rodando em segundo plano. Feche-o primeiro: no Mac, procure o ícone do Ollama na barra de menus e escolha Sair; no Windows, ache-o na bandeja do sistema. Depois rode o comando acima novamente.
Passo 2. Instale o SurfMind na Chrome Web Store e abra-o em qualquer página.
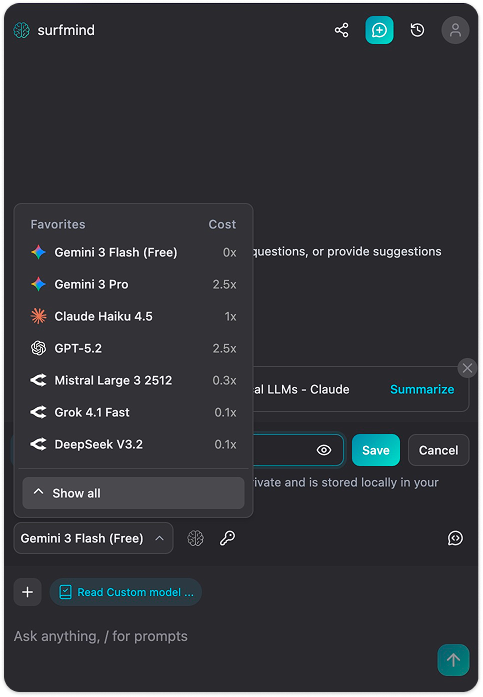
Passo 3. Clique no nome do modelo na parte inferior do painel do SurfMind para abrir seus Favoritos, depois mude para a aba Custom.
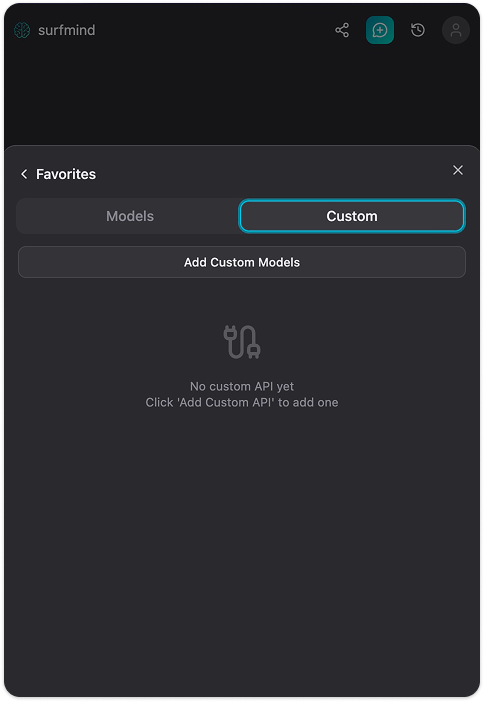
Passo 4. Clique em Add Custom Models. Um formulário "Custom Model API" aparecerá. Clique na seta dropdown perto do campo API Name, você verá um menu Presets com Ollama listado. Selecione Ollama e ele preencherá todos os campos automaticamente:
- API URL:
http://localhost:11434/api/chat - Models URL:
http://localhost:11434/api/tags - API Key Header: Nenhum
- API Key: (deixe vazio)
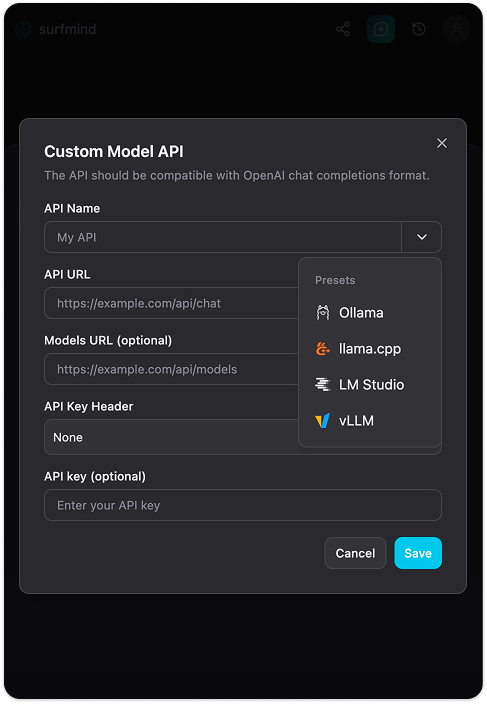
Passo 5. Clique em Save. O SurfMind se conectará à sua instância local do Ollama e buscará a lista dos modelos instalados. Eles aparecerão na seção Ollama, prontos para selecionar.
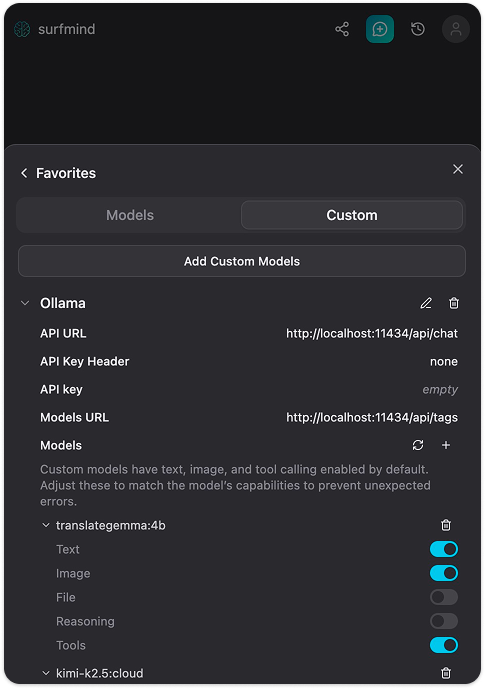
Agora navegue para qualquer página web, abra o SurfMind, escolha seu modelo Ollama no seletor de baixo e comece a fazer perguntas sobre o que está na página. É só isso.
Alguns exemplos práticos para experimentar
Para pesquisadores e estudantes: Abra qualquer artigo acadêmico e pergunte "qual é o principal argumento aqui?" ou "quais limitações os autores reconhecem?" Você se orienta em segundos em vez de passar o artigo todo procurando a seção relevante.
Para desenvolvedores: Abra documentações com as quais você está trabalhando e pergunte dúvidas específicas. Ótimo para navegar em APIs ou frameworks desconhecidos sem quebrar seu fluxo para abrir uma janela de chat separada.
Para uso empresarial: Aponte para relatórios financeiros, releases, páginas de concorrentes ou análises do setor. Pergunte o que chama atenção, o que falta ou que dúvidas surgem. Para análises pesadas, troque para um modelo em nuvem para maior profundidade.
Para uso diário com foco em privacidade: Sempre que você fosse colar algo no ChatGPT mas hesita por causa do conteúdo, essa é a alternativa.
Algumas ressalvas honestas
Nenhuma ferramenta de IA é infalível. Modelos ocasionalmente produzem respostas confiantes que estão erradas. Isso é uma limitação de todos os modelos de linguagem, não um problema específico de rodar localmente. Para qualquer coisa que exija precisão, como análises legais, perguntas médicas, decisões financeiras, trate o resultado como um ponto de partida a ser verificado, não como uma resposta final.
Dito isso, a qualidade evoluiu bastante. Modelos locais menores lidam bem com a maioria das tarefas do dia a dia, e se precisar de mais potência, os modelos em nuvem do Ollama diminuem bastante essa diferença.
Vale a pena tentar, mesmo que só uma vez
O espaço de IA local amadureceu mais rápido do que a maioria imagina. Há um ano isso exigia esforço técnico significativo. Hoje, você está a dois comandos de terminal e uma extensão de navegador de um assistente de IA capaz que funciona em qualquer página da web, de forma privada, gratuita e completamente nos seus próprios termos.
Se você estava curioso para montar seu próprio setup de IA mas achava que era complicado demais, Ollama é o que torna isso acessível. Instale-o esta tarde. Baixe um modelo. Abra o SurfMind no próximo artigo que ia ler de qualquer jeito. Veja como muda a experiência.
E se experimentar, nos conte para que acabou usando. Os casos de uso que as pessoas encontram são sempre mais criativos do que imaginamos.
Seu modelo de IA local está rodando. Agora coloque-o para trabalhar em cada página que você navegar.
Posts recentes
Ver tudo
O Guia Prioritário de Privacidade para Usar Extensões de IA no Seu Navegador
Como usar extensões de IA no navegador sem sacrificar sua privacidade? Descubra BYOK, armazenamento local e controles granulares que protegem seus dados.

Como exportar chats de IA para o Obsidian
Aprenda como exportar mensagens selecionadas de chat com IA para o Obsidian com o SurfMind e salve conversas úteis como notas Markdown organizadas no seu vault.
Como exportar chats de IA para o Notion
Aprenda a exportar mensagens selecionadas de chats de IA para o Notion com o SurfMind e transformar conversas úteis em conhecimento organizado.