如何使用 Ollama 与任何网页聊天

你可能已经注意到了变化。ChatGPT 无处不在,但围绕它的不安也在逐渐增加。你粘贴进去的文档会发生什么?谁会阅读你的提示?你的雇主或客户能否辨别你是否使用过它?
这些都是合理的问题。而且越来越多的人已经悄悄不再问这些问题,因为他们已经将 AI 设置迁移到了本地。
这篇文章正是讲这个的。我们将介绍 Ollama 是什么、如何设置、哪些模型值得使用,然后进入真正令人兴奋的部分:在浏览器内直接使用 AI 与任何你正在阅读的网页互动。无需订阅。除非你愿意,否则数据不会离开你的设备。
无论你是开发者、研究人员、记者,还是仅仅对 AI 好奇且不喜欢每条查询都被记录的普通用户,这篇都适合你。
首先——什么是 Ollama?
Ollama 是一个免费开源工具,允许你直接在自己的电脑上下载并运行大型语言模型。无论是 Mac、Windows 还是 Linux,通通支持。
把它想象成模型管理器。你选择一个模型,下载一次,从此它完全运行在你的硬件上。无需互联网连接。没有使用费用。没有第三方服务器处理你的查询。
在 ChatGPT 首次发布时,强大的 AI 模型只能通过云服务访问。现在,你可以完全本地且私密地运行相当的模型,或者如果你需要更强大的算力,可以在不切换工具或改变工作流程的情况下,使用 Ollama 的云服务。后面会详细介绍。
实际好处超过想象。你可以输入敏感文件、私人笔记、保密网页,取决于你使用的模式,这些内容无需传输到任何地方。这也意味着你不必为按令牌计费而不断积累的月度费用买单。
人们实际使用 Ollama 做什么?
在进入设置之前,先用真实用例来解释,因为“本地运行 AI”听起来抽象。
人们用本地模型做的事很广泛:总结长篇报告、写邮件草稿、调试代码、不想让查询被存储时做研究、分析合同、处理会议笔记。开发者用它在受控环境里测试模型行为。作家用它在不担心作品被用作训练数据的情况下获取草稿反馈。学生用它在不烧订阅的前提下深入复杂主题。
共同点是对“掌控”的需求。使用 Ollama 的人往往希望在自己的条件下 与 AI 协作,而不是通过可能随时涨价、限速或记录会话的订阅门户。
设置 Ollama
你需要什么
不必顶尖配置,但内存很关键。推荐至少 16GB 内存,以顺畅运行大多数模型。8GB 可用,但只能选最小的模型,响应可能较慢。如果你使用带 Apple Silicon 的 Mac,情况特别好,因为统一内存架构极高效地支持本地 AI。Windows 和 Linux 也非常兼容。
安装步骤
Ollama 支持主流平台(macOS、Linux、Windows)。最简单的安装方式是:
# On macOS or Linux
curl -fsSL https://ollama.com/install.sh | sh
# Or use Homebrew on macOS
brew install ollama
# On Windows, download the installer from Ollama’s website https://ollama.com/download/windows安装后,Ollama 会在后台启动本地服务器,端口是 11434。打开浏览器访问 http://localhost:11434 即可验证是否运行正常,页面上会出现确认信息。
下载你的第一个模型
打开终端,输入:
ollama pull llama3.2这会把 Meta 的 Llama 3.2 模型下载到你的机器(约 2GB)。run 命令也会自动处理下载,所以你可以直接执行:
ollama run llama3.2输入你的问题,得到回答。你现在已能在本地硬件上运行一个功能强大的语言模型。
选用哪个模型?
Ollama 库中有 100 多个模型,刚看时可能会令人眼花缭乱。这里给你一个实用入门指引:
| 模型 | 适用场景 | 需要内存 |
|---|---|---|
gemma3:2b |
旧款或低配置机器 | ~4GB |
llama3.2 |
一般日常使用 | ~8GB |
mistral |
速度和编程任务 | ~8GB |
deepseek-r1 |
分析、推理、研究 | ~8GB |
llama3.3:70b |
最大本地能力 | ~32GB+ |
如果刚开始,llama3.2 是最佳选择。它速度快,表现均衡,且适合大多数现代笔记本。
用以下命令查看你安装的模型列表:
ollama list值得注意的是:这些模型的知识截止于特定时间点,无法访问实时信息。比如当前阅读的网页内容,你需要直接提供给模型上下文。这正是我们即将介绍的内容。
如果你需要更大、更强的模型怎么办?
本地模型很强,但受硬件限制。70B 参数模型需要大量内存,671B 参数模型根本不可能在个人电脑上运行。
这时可用 Ollama 的云模型。2025 年末发布,它让你用相同的 Ollama 界面运行数据中心级的大型模型。命令相同、API 不变,工具不换。
ollama run deepseek-v3.1:671b-cloud云模型选项包括:
deepseek-v3.1:671b-cloud:目前最强劲的开源权重模型之一qwen3-coder:480b-cloud:专为编码任务设计gpt-oss:120b-cloud和gpt-oss:20b-cloud:OpenAI 公开权重模型
云模型表现与本地模型一致,唯一差别是需先登录 ollama.com:
ollama signin并且重要的是:Ollama 云不会保存你的数据。你可以拥有大型云模型的强大能力,而无需担心通常的隐私折衷。
实际建议是:本地模型用于敏感工作,确保数据不离机;需要极强能力时切换云模型。Ollama 顺滑支持两者,只需选带 -cloud 后缀的模型标签。
真正改变工作方式的部分:与网页聊天
精彩来了。
单独的 Ollama 很有用,但把它和浏览器连接起来,让你能针对任何网页内容提问,才是工作流程从“有趣实验”转变为“每天都用”的关键。
想想这带来的可能:
- 阅读复杂研究论文? 请模型总结方法、用白话解释结论,或指出任何牵强之处。
- 审阅竞争对手定价页面? 询问差异点,或者遗漏了什么。
- 浏览长篇新闻报道? 摘出关键论点,确认标题是否准确,了解反面观点。
- 查看招聘信息? 判断自己的经验是否匹配岗位描述。
- 处理法律文件或服务条款? 用通俗语言解读,无需将敏感文字贴到云端工具。
一切都由你掌控。页面内容只传给你选定的模型。
如何用 SurfMind 实现
SurfMind 是一个为此专门打造的浏览器扩展。它能读取你所在网页的内容,让你直接在浏览器内与之进行真实对话,无需复制粘贴。
它开箱即用支持本地 Ollama 模型,以及 Ollama 云模型,提供一个强大的 AI 助手,跨全网运作且由你掌控。
连接步骤如下:
步骤 1. 启动 Ollama 前,运行这条一次性命令,开启浏览器访问:
# Mac/Linux
OLLAMA_ORIGINS="*" ollama serve
# Windows (PowerShell)
$env:OLLAMA_ORIGINS="*"; ollama serve出现“端口 11434 已被占用”错误? 说明 Ollama 应用已在后台运行。先关闭它,Mac 上点击菜单栏 Ollama 图标选择退出;Windows 右下系统托盘找到 Ollama 图标退出。然后重新运行上述命令。
步骤 2. 从 Chrome 网上应用店安装 SurfMind,并在任意页面打开扩展。
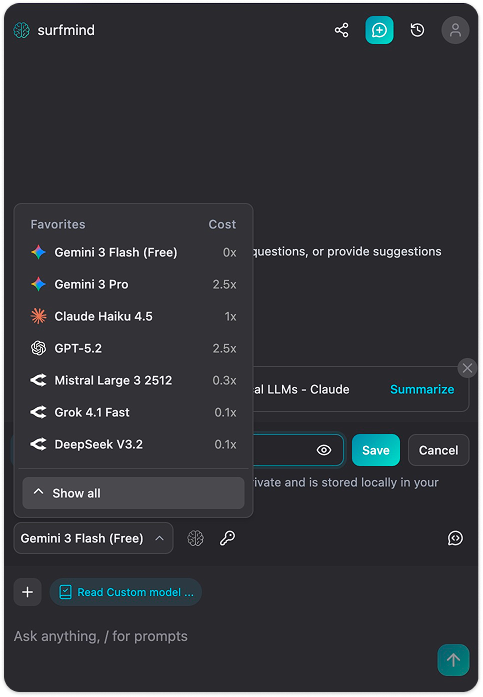
步骤 3. 点击 SurfMind 面板底部的模型名称,打开收藏夹,再切换到 自定义 标签页。
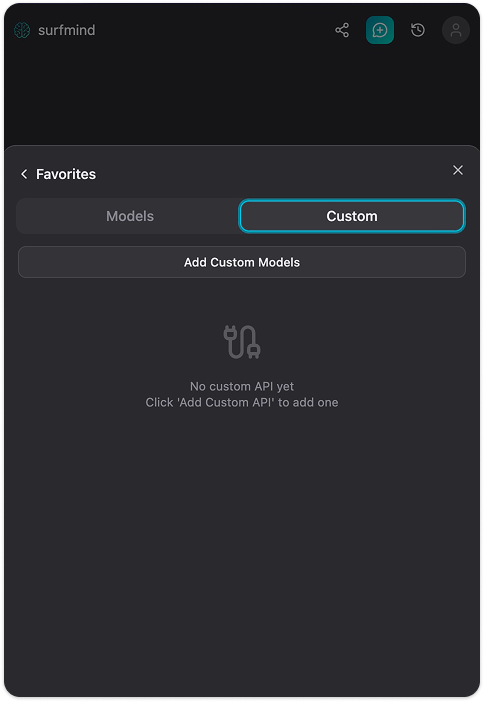
步骤 4. 点击 添加自定义模型,弹出“自定义模型 API”表单。点击“API 名称”字段旁边的下拉箭头,会看到已有的预设菜单,其中直接有 Ollama。选择 Ollama,各字段会自动填写:
- API URL:
http://localhost:11434/api/chat - Models URL:
http://localhost:11434/api/tags - API 密钥头: 无
- API 密钥: 留空
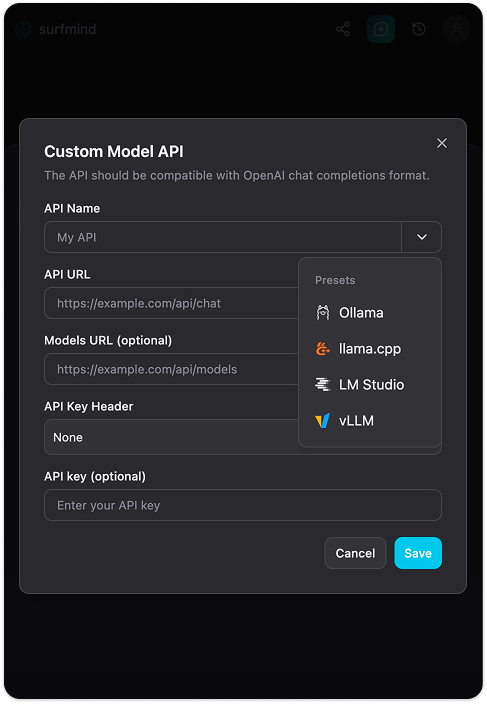
步骤 5. 点击 保存。SurfMind 将连接到本地 Ollama 实例,拉取你已安装的模型列表。它们会显示在 Ollama 区域,等你选择。
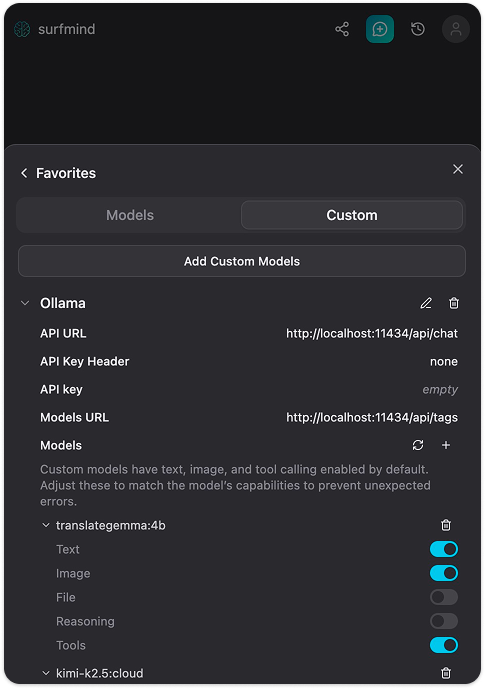
这时,浏览任意网页,打开 SurfMind,从底部切换器选中你想用的 Ollama 模型,开始提问关于页面的内容。完成!
一些值得尝试的实际应用示例
针对研究人员和学生: 打开任何学术文章,问“这里的主要论点是什么?”或“作者承认了哪些局限?”你能在几秒内找到方向,而不必全文浏览找相关部分。
开发者: 打开文档提问具体问题。非常适合浏览不熟悉的 API 或框架,避免分心去开聊天窗口。
商务场景: 指向财报、新闻稿、竞争对手网页或行业分析。询问重点、遗漏,或会引发什么问题。需要深入分析时,可以切换云模型。
注重隐私的日常使用: 凡是你犹豫要不要把内容粘贴进 ChatGPT 的场景,这里是替代方案。
一些诚实的告诫
没有 AI 工具是绝对准确的。模型偶尔会生成自信但错误的回答。这是所有语言模型的通病,而非本地专属问题。涉及法律分析、医疗问题、财务决策时,务必将输出视为一个需要核实的起点,而非最终结论。
但不可否认,质量已大幅提升。中小型本地模型能很好处理大多数日常任务,如果需要更强性能,Ollama 云模型能极大缩小差距。
值得一试——即使只有一次
本地 AI 领域的发展比大多数人想象的要快。一年前这还需要一定技术门槛。今天,只需两个终端命令加一个浏览器扩展,你就拥有一个可在任意网页上私密工作、免费又完全受控的强力 AI 助手。
如果你一直好奇自建 AI 环境,但觉得太复杂,Ollama 能帮你轻松上手。今天下午安装,下载一个模型,用 SurfMind 打开你本来准备看的下一篇文章,感受它带来的改变。
如果你试用了,也欢迎告诉我们你的使用场景。人们的创造力总超出我们的预期。
你的本地 AI 模型已经运行。现在就让它在你浏览的每个页面上发挥作用。