Ein lokales LLM oder eine eigene KI mit SurfMind in deinen Browser bringen
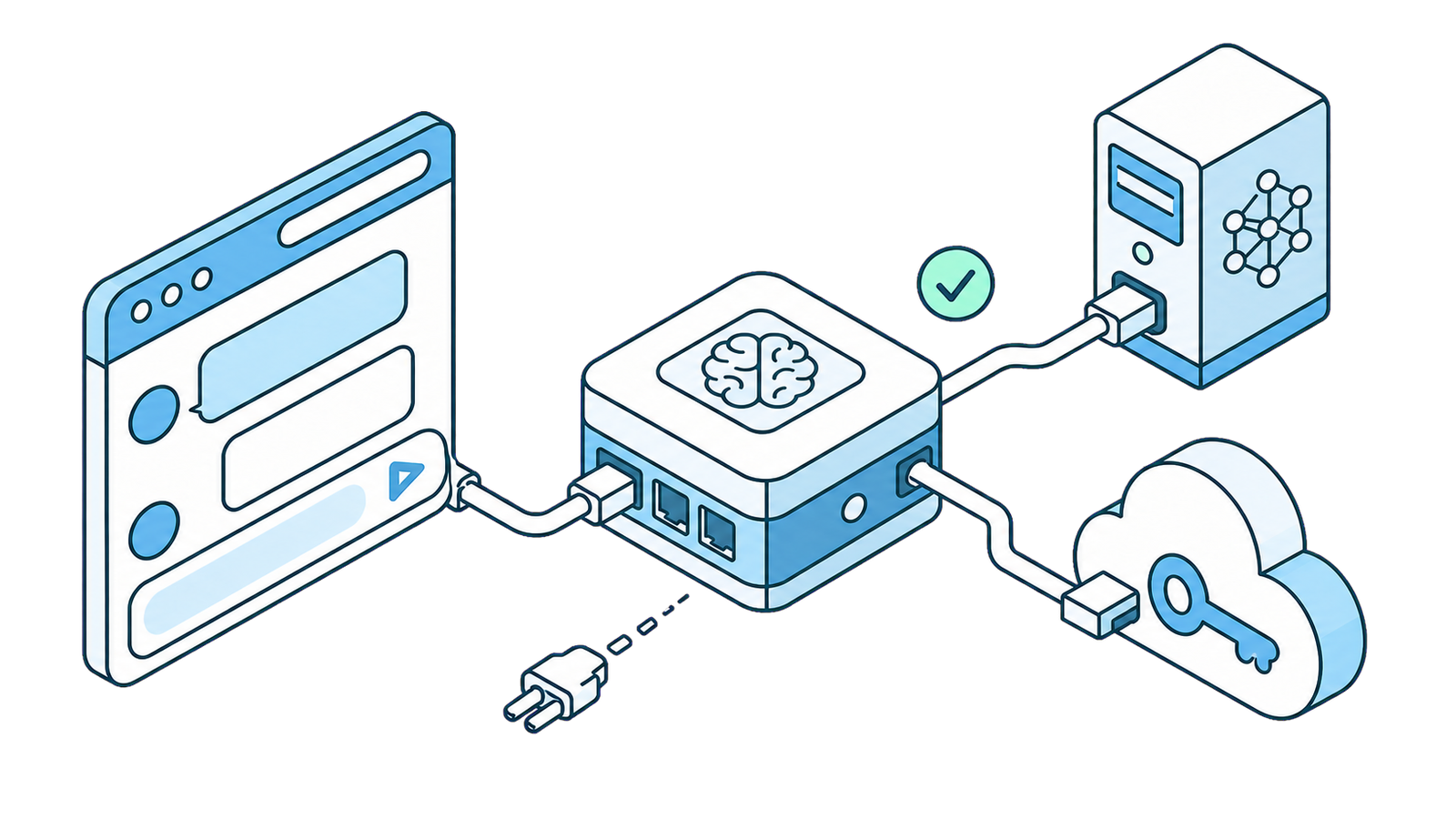
SurfMind sperrt dich nicht in einen festen Satz von Modellen ein. Über die Custom Model API kannst du es auf ein Modell richten, das auf deinem eigenen Rechner läuft (Ollama, LM Studio, Jan, llama.cpp, vLLM), oder auf nahezu jeden externen KI-Anbieter, der die OpenAI-Completion-API spricht — Poe, z.ai, Together, Groq, DeepSeek, AWS Bedrock und Dutzende mehr.
Der Haken: Wenn es beim ersten Versuch nicht klappt, steckt oft ein kleiner Konfigurationsfehler dahinter. Und die Fehlermeldung, die du zurückbekommst ("connection failed", "401", "404", "model not found"), hilft nicht immer weiter.
Dieser Beitrag ist eine schnelle Prüfung und ein Selbsthilfe-Leitfaden. Überfliege die Checkliste und kontrolliere dein Setup. Wenn es immer noch nicht funktioniert, schreib uns eine E-Mail an wave@surfmind.ai.
Suchst du nach einem bestimmten Anbieter? Schau in unsere Liste: lokale Modelle (Ollama, LM Studio, Jan…) oder KI-Anbieter (Poe, z.ai, Together, Groq, AWS…).
Die 60-Sekunden-Checkliste
Bevor du irgendetwas anderes machst, geh diese Punkte durch. Die meisten Setup-Probleme lassen sich auf einen davon zurückführen:
- Läuft der Server überhaupt? Bei lokalen Modellen muss der Runner (Ollama, LM Studio usw.) gestartet sein und ein Modell geladen haben.
- Stimmt der Port? Ollama ist
11434. LM Studio ist1234. Sie sind nicht austauschbar, und das ist der mit Abstand häufigste Fehler. - Stimmt der Pfad? Ollamas nativer Pfad ist
/api/chat. Fast alles andere ist/v1/chat/completions. Verwechselst du sie, bekommst du einen Fehler. - Hast du den vollständigen Endpunkt eingefügt, nicht nur die Basis? Das API URL-Feld von SurfMind erwartet die vollständige URL, die auf
/chat/completionsendet (oder/api/chatfür Ollama), nicht nurhttps://api.provider.com/v1. - Stimmen der API-Schlüssel (und dessen Header)? Lokale Runner brauchen meist keinen Schlüssel. Externe Anbieter brauchen
Authorizationals Header und deinen echten Schlüssel als Wert. - Für lokale Modelle im Browser: ist CORS erlaubt? Das ist der eine zusätzliche Schritt, den lokale Setups brauchen (
OLLAMA_ORIGINSoder "Enable CORS" in LM Studio).
Wenn du danach immer noch feststeckst, lies weiter — jeder dieser Punkte hat eine subtile Variante, über die Leute stolpern.
Was in jedes Feld gehört
Wenn du den Tab Custom öffnest → Add Custom Models, erscheint das Formular "Custom Model API". Hier steht genau, was jedes Feld erwartet:
| Feld | Was einzutragen ist |
|---|---|
| API Name | Beliebige Bezeichnung (z. B. "Groq" oder "Mein Ollama"). Klick auf den Dropdown-Pfeil, um ein Preset zu laden — Ollama und eine generische OpenAI-kompatible Option füllen den Rest automatisch für dich aus. |
| API URL | Der vollständige Chat-Endpunkt, nicht die Basis-URL. Für Ollama ist das http://localhost:11434/api/chat; für alle anderen endet er auf /chat/completions. Siehe Fehler #1. |
| Models URL (optional) | Der Endpunkt, der die verfügbaren Modelle auflistet, damit SurfMind sie in einem Dropdown anzeigen kann, statt dich Namen tippen zu lassen. Ollama: /api/tags. OpenAI-kompatibel: /v1/models. Leer lassen, wenn der Anbieter keinen Listen-Endpunkt hat — dann tippst du die Modell-ID einfach selbst. |
| API Key Header | Wie dein Schlüssel gesendet wird. None = keine Authentifizierung (lokale Modelle). Authorization = Authorization: Bearer <key>, was nahezu jeder Cloud-Anbieter verwendet. x-api-key = x-api-key: <key>, verwendet von Anthropic-artigen APIs und einigen anderen. |
| API Key (optional) | Der Schlüssel selbst — nicht mehr. Tippe nicht das Wort Bearer; SurfMind fügt es hinzu. Bei lokalen Modellen leer lassen. |
Die beiden Felder, bei denen Leute Fehler machen, sind API URL (Basis vs. vollständiger Endpunkt) und API Key Header (welcher Header). Der Rest dieses Leitfadens geht genau darauf ein.
Fehler #1: der API-URL-Pfad (die /api/chat- vs. /v1/chat/completions-Falle)
Das ist der große Brocken, und es lohnt sich zu verstehen, warum er passiert.
Es gibt zwei verschiedene API-"Dialekte" in dieser Welt:
- Ollamas native API, die
http://localhost:11434/api/chatverwendet. - Die OpenAI-Completion-API, die
.../v1/chat/completionsverwendet. Die sprechen LM Studio, vLLM, Jan, Poe, z.ai, Together, Groq — im Grunde alle anderen.
Wenn du also eine für LM Studio geschriebene Anleitung kopierst und versuchst, diesen Pfad mit Ollama (oder umgekehrt) zu verwenden, bekommst du einen 404, obwohl der Server einwandfrei läuft. Der Server ist online; du klopfst nur an die falsche Tür.
| Runner / Anbieter | Korrekte API URL |
|---|---|
| Ollama (nativ) | http://localhost:11434/api/chat |
| Ollama (OpenAI-kompatibler Modus) | http://localhost:11434/v1/chat/completions |
| LM Studio | http://localhost:1234/v1/chat/completions |
| Alle OpenAI-kompatiblen | https://<host>/v1/chat/completions |
Gut zu wissen: Ollama spricht tatsächlich beide Dialekte. Das Ollama preset in SurfMind verwendet den nativen
/api/chat-Pfad, der der einfachste Weg ist und dir die automatische Modellerkennung liefert. Du brauchst Ollamas/v1/chat/completions-Pfad nur, wenn ein Tool ausdrücklich das OpenAI-Format verlangt. Für SurfMind nimm einfach das Preset.
Fehler #2: die Portnummer
Jeder lokale Runner wählt seinen eigenen Standard-Port, und sie sehen sich ähnlich genug, um sich zu vertippen:
| Tool | Standard-Port | Vollständige Chat-URL |
|---|---|---|
| Ollama | 11434 |
http://localhost:11434/api/chat |
| LM Studio | 1234 |
http://localhost:1234/v1/chat/completions |
| Jan | 1337 |
http://localhost:1337/v1/chat/completions |
llama.cpp (llama-server) |
8080 |
http://localhost:8080/v1/chat/completions |
| vLLM | 8000 |
http://localhost:8000/v1/chat/completions |
| LocalAI | 8080 |
http://localhost:8080/v1/chat/completions |
11434 vs. 1234 ist die klassische Verwechslung — auf den ersten Blick leicht zu verwechseln, aber eine Ziffer daneben und nichts verbindet sich. Wenn du den Port selbst geändert hast (z. B. vLLM mit --port 9000 gestartet), verwende deinen Port, nicht den Standard.
Schnelle Plausibilitätsprüfung: öffne den Port in deinem Browser. Der Aufruf von http://localhost:11434 sollte Ollamas Meldung "Ollama is running" anzeigen. Wenn die Seite gar nicht lädt, läuft der Server nicht oder du hast den falschen Port.
Fehler #3: die Basis-URL statt des Endpunkts eingefügt
Anbieter-Dokumentationen geben dir fast immer eine Basis-URL — etwas wie https://api.poe.com/v1. Das liegt daran, dass ihre Code-Beispiele das OpenAI-SDK verwenden, das /chat/completions im Hintergrund für dich anhängt.
Das API URL-Feld von SurfMind macht das nicht für dich. Es erwartet den vollständigen Endpunkt. Du musst den Pfad also selbst hinzufügen:
- Basis-URL aus der Doku:
https://api.poe.com/v1 - Was du in SurfMind einfügst:
https://api.poe.com/v1/chat/completions
Dasselbe gilt für das Models URL-Feld (das die verfügbaren Modelle automatisch auflistet): nimm die Basis und häng /models an → https://api.poe.com/v1/models.
Zwei verwandte Stolperfallen:
- Doppeltes
/v1. Wenn die Basis bereits auf/v1endet, füge kein weiteres hinzu..../v1/v1/chat/completionsist ein 404. - Abschließende Schrägstriche.
.../chat/completions/mit einem abschließenden Schrägstrich kann auf manchen Servern fehlschlagen. Lass ihn weg.
Fehler #4: die Models URL passt nicht zur API URL
Die Models URL ist optional. Das ist der Endpunkt, den SurfMind aufruft, um die Liste der von einem Anbieter angebotenen Modelle abzurufen und sie dir in einem Dropdown anzuzeigen, statt dich Namen tippen zu lassen. Wenn deine Modelle nach dem Speichern nicht im Auswahlfeld auftauchen, ist meist dieses Feld der Übeltäter. Es muss demselben Dialekt folgen wie der Chat-Endpunkt:
| Dialekt | Models URL |
|---|---|
| Ollama (nativ) | http://localhost:11434/api/tags |
| OpenAI-kompatibel (alle anderen) | https://<host>/v1/models |
Ein häufiger Fehler ist das Vermischen — /api/tags bei einem OpenAI-kompatiblen Anbieter zu verwenden, oder /v1/models beim nativen Ollama-Preset. Wenn du das Ollama preset verwendet hast, ist das korrekt für dich ausgefüllt; lass es unverändert.
Wann du es leer lassen solltest: manche Anbieter stellen keinen öffentlichen Endpunkt zur Modellauflistung bereit oder blockieren ihn. Das ist in Ordnung — lass die Models URL leer und tippe einfach die exakte Modell-ID selbst ins Modellfeld (siehe Fehler #7). Der Chat funktioniert trotzdem; du bekommst nur kein automatisch befülltes Dropdown.
Fehler #5: der API Key Header (Bearer vs. x-api-key)
Das API Key Header-Dropdown entscheidet, wie dein Schlüssel an die Anfrage angehängt wird. Wählst du den falschen, bekommst du einen 401 Unauthorized — selbst mit einem völlig gültigen Schlüssel. Es gibt drei Optionen:
| API Key Header | Was SurfMind sendet | Wofür |
|---|---|---|
| None | nichts | Lokale Modelle brauchen meist keine Authentifizierung, aber es lohnt sich, dein konkretes Setup zu prüfen. |
| Authorization | Authorization: Bearer <your key> |
Fast jeder Cloud-Anbieter: Poe, z.ai, Together, Groq, DeepSeek, Mistral, Fireworks, xAI, AWS Bedrock. Das ist der Standard für OpenAI-kompatible APIs. |
| x-api-key | x-api-key: <your key> |
Anthropic-artige APIs und eine Handvoll Anbieter, die einen rohen Schlüssel-Header statt eines Bearer-Tokens erwarten. |
Das API Key-Feld nimmt dann nur den Schlüssel selbst:
- Tippe nicht das Wort
Bearer— SurfMind fügt es hinzu, wenn du Authorization wählst. - Lass kein abschließendes Leerzeichen stehen (eine überraschend häufige Ursache für 401-Fehler).
- Bei lokalen Modellen leer lassen. (LM Studio ist die Ausnahme — es will irgendeinen nicht-leeren Wert; die eigene Doku verwendet
lm-studio.)
Wenn du unsicher bist, welchen Header ein Anbieter verwendet: 99 % der OpenAI-kompatiblen Anbieter verwenden Authorization. Greif nur zu x-api-key, wenn die Doku des Anbieters ausdrücklich einen x-api-key-Header zeigt. Bekommst du immer noch einen 401? Generiere den Schlüssel neu, prüf die Header-Wahl doppelt und stell sicher, dass kein verirrtes Leerzeichen drin ist.
Fehler #6: CORS — die Stolperfalle nur für lokale Setups
Browser weigern sich, einen lokalen Server aufzurufen, sofern dieser Server Anfragen von der Erweiterung nicht ausdrücklich erlaubt. Das betrifft speziell lokale Setups (externe Anbieter erlauben es bereits).
Ollama: starte es mit aktiviertem Browser-Zugriff:
# Mac/Linux OLLAMA_ORIGINS="*" ollama serve # Windows (PowerShell) $env:OLLAMA_ORIGINS="*"; ollama serve"port 11434 already in use"? Die Ollama-Hintergrund-App läuft bereits. Beende sie zuerst (Menüleiste auf dem Mac, System-Tray unter Windows) und führe dann den obigen Befehl aus.
LM Studio: Aktiviere im Tab Developer / lokaler Server die Option Enable CORS, bevor du den Server startest.
Noch eine Feinheit: Wenn localhost keine Verbindung herstellt, versuch stattdessen 127.0.0.1 (oder umgekehrt). Auf manchen Systemen werden sie nicht gleich aufgelöst.
Fehler #7: der Modellname muss exakt übereinstimmen
Sobald du verbunden bist, muss der von dir ausgewählte Modellname exakt dem entsprechen, was der Anbieter erwartet — einschließlich Groß- und Kleinschreibung. Das ärgert Leute bei Anbietern, die Modelle nicht automatisch auflisten oder ungewöhnliche Benennungen verwenden:
- Poe verwendet Bot-Namen im Anzeigeformat wie
Claude-Sonnet-4.6undGPT-5.4— kopiere sie genau so, wie sie auf Poe erscheinen. - z.ai verwendet IDs wie
glm-4.6undglm-5. - Together AI verwendet IDs mit Namespace-Präfix:
meta-llama/Llama-3.3-70B-Instruct-Turbo,deepseek-ai/DeepSeek-V3. - Fireworks verwendet eine vollständige Pfad-ID:
accounts/fireworks/models/llama-v3p3-70b-instruct.
Wenn die Verbindung funktioniert, du aber "model not found" bekommst, ist es fast immer ein Tippfehler im Namen oder falsche Groß-/Kleinschreibung. Wenn SurfMind Modelle über die Models URL automatisch auflisten kann, wähl aus der Liste, statt zu tippen.
Schnellreferenz: lokale Modelle
Diese laufen alle auf deinem eigenen Rechner. Öffne den Custom-Tab von SurfMind → Add Custom Models, wähl das passende Preset (Ollama hat sein eigenes; der Rest verwendet das generische OpenAI-compatible-Preset) und setze API Key Header auf None. Die Anbieternamen verlinken auf die Setup-Doku des jeweiligen Tools.
- API URL:
http://localhost:11434/api/chat - Models URL:
http://localhost:11434/api/tags - API-Schlüssel: keiner
- API URL:
http://localhost:1234/v1/chat/completions - Models URL:
http://localhost:1234/v1/models - API-Schlüssel: beliebiger nicht-leerer Wert (z. B.
lm-studio)
- API URL:
http://localhost:1337/v1/chat/completions - Models URL:
http://localhost:1337/v1/models - API-Schlüssel: keiner (oder dein Jan-Schlüssel)
- API URL:
http://localhost:8080/v1/chat/completions - Models URL:
http://localhost:8080/v1/models - API-Schlüssel: keiner (außer du hast es mit
--api-keygestartet)
- API URL:
http://localhost:8000/v1/chat/completions - Models URL:
http://localhost:8000/v1/models - API-Schlüssel: dein
--api-key, falls du einen gesetzt hast
- API URL:
http://localhost:8080/v1/chat/completions - Models URL:
http://localhost:8080/v1/models - API-Schlüssel: keiner
Vergiss bei keinem davon den CORS-Schritt (Fehler #6). Speziell für Ollama findest du die vollständige Anleitung mit Screenshots in unserem Ollama-Leitfaden, und falls du dich zwischen den ersten beiden entscheidest, siehe Ollama vs. LM Studio.
Schnellreferenz: beliebte KI-Anbieter
Diese Cloud-Anbieter sprechen alle die OpenAI-kompatible API. Verwende das generische OpenAI-compatible-Preset, setze den API Key Header auf Authorization (sie alle verwenden Bearer-Tokens) und füge deinen Schlüssel ein. Die Anbieternamen verlinken auf die API-Doku des jeweiligen Anbieters.
Poe — ein Schlüssel für Hunderte von Modellen (Claude, GPT, Gemini, Llama…), abgerechnet über die Punkte deines Poe-Abonnements. Die Modellnamen sind Bot-Namen im Anzeigeformat — kopiere sie genau so, wie sie auf Poe angezeigt werden (z. B. Claude-Sonnet-4.6, GPT-5.4). Schlüssel von poe.com → Settings → API key.
- API URL:
https://api.poe.com/v1/chat/completions - Models URL:
https://api.poe.com/v1/models
CanopyWave — GPU-Cloud-Anbieter, der offene Modelle bereitstellt (Kimi, DeepSeek, Llama, Qwen). Schlüssel aus dem CanopyWave-Dashboard.
- API URL:
https://inference.canopywave.io/v1/chat/completions - Models URL:
https://inference.canopywave.io/v1/models
z.ai (GLM) — Zhipus GLM-Modelle (glm-4.6, glm-5). Achtung: z.ai veröffentlicht außerdem einen separaten Coding-Plan-Endpunkt (https://api.z.ai/api/coding/paas/v4) und einen PaaS-Endpunkt (https://api.z.ai/api/paas/v4) — verwende den unten stehenden OpenAI-kompatiblen und füge kein zusätzliches /v1 hinzu.
- API URL:
https://api.z.ai/api/openai/v1/chat/completions - Models URL:
https://api.z.ai/api/openai/v1/models
Together AI — großer Katalog offener Modelle. Modell-IDs sind lang (meta-llama/Llama-3.3-70B-Instruct-Turbo) — kopiere sie genau von Togethers Modellseite.
- API URL:
https://api.together.xyz/v1/chat/completions - Models URL:
https://api.together.xyz/v1/models
Groq — extrem schnelle Inferenz. Stolperfalle: der Pfad ist /openai/v1, nicht nur /v1.
- API URL:
https://api.groq.com/openai/v1/chat/completions - Models URL:
https://api.groq.com/openai/v1/models
DeepSeek — aktuelle Modelle sind deepseek-v4-flash und deepseek-v4-pro (die älteren Aliase deepseek-chat / deepseek-reasoner werden eingestellt — den aktuellen Stand findest du in DeepSeeks Doku). Das /v1 ist optional; DeepSeek akzeptiert die URL mit oder ohne.
- API URL:
https://api.deepseek.com/v1/chat/completions - Models URL:
https://api.deepseek.com/v1/models
Mistral — mistral-large-latest, mistral-small-latest usw. Standard-OpenAI-kompatibel.
- API URL:
https://api.mistral.ai/v1/chat/completions - Models URL:
https://api.mistral.ai/v1/models
Fireworks AI — Stolperfalle: der Pfad ist /inference/v1, nicht /v1. Modell-IDs sehen aus wie accounts/fireworks/models/llama-v3p3-70b-instruct.
- API URL:
https://api.fireworks.ai/inference/v1/chat/completions - Models URL:
https://api.fireworks.ai/inference/v1/models
xAI (Grok) — Grok-Modelle (grok-4 usw.). Standard-OpenAI-kompatibel.
- API URL:
https://api.x.ai/v1/chat/completions - Models URL:
https://api.x.ai/v1/models
AWS Bedrock — Bedrock hat jetzt einen OpenAI-kompatiblen Endpunkt, aber mit zwei Stolperfallen: der Host ist regionsspezifisch (z. B. us-west-2) und der Pfad ist /openai/v1. Du musst einen Bedrock API key verwenden (ein Bearer-Token, das du in der Konsole generierst) — nicht deine normalen AWS-Access-Keys/SigV4. Modell-IDs sehen aus wie openai.gpt-oss-120b-1:0.
- API URL:
https://bedrock-runtime.<region>.amazonaws.com/openai/v1/chat/completions - Models URL: leer lassen — Modell-ID später eingeben
Verbindet sich immer noch nicht? Letzte Triage
Arbeite diese Liste durch:
- Öffne den Host der API URL in deinem Browser. Lokaler Server lädt nicht → er läuft nicht oder der Port ist falsch.
- Lies den Pfad noch einmal. Ollama →
/api/chat. Alle anderen →/v1/chat/completions(oder der spezielle Pfad des Anbieters aus der Tabelle). - Bestätige, dass du den vollständigen Endpunkt eingefügt hast, nicht die Basis, und dass es kein doppeltes
/v1oder einen abschließenden Schrägstrich gibt. - 401? Es ist der Schlüssel oder der Header. Header =
Authorization, Schlüssel ohne Leerzeichen, keinBearer-Präfix. - 404 "model not found"? Die Verbindung ist in Ordnung — korrigiere den Modellnamen (exakte Schreibweise).
- Lokales Modell, vom Browser blockiert? Aktiviere CORS (
OLLAMA_ORIGINS="*"oder den Schalter in LM Studio) und versuch127.0.0.1stattlocalhost.
Diese Reihenfolge behebt das Problem bei den allermeisten Setups.
Brauchst du noch Hilfe?
Wenn du die Checkliste durchgearbeitet hast und sich dein Anbieter immer noch nicht verbinden will, schreib uns an wave@surfmind.ai mit dem Anbieter, den du versuchst, und der Fehlermeldung, die du siehst. Wir helfen dir, die Verbindung herzustellen.
Verbindung hergestellt? Öffne SurfMind auf der nächsten Seite, die du lesen wolltest, und setze dein Modell an die Arbeit.
Neueste Beiträge
Alle anzeigen
Private KI in Firefox: Lokale Modelle mit null Telemetrie ausführen
Füge Firefox einen privaten KI-Assistenten hinzu, der auf lokalen Modellen läuft, damit dein Seiteninhalt nie deinen Rechner verlässt. Keine Telemetrie, keine Cloud, kein Kompromiss.

Die besten Browser-Erweiterungen für lokale KI-Modelle 2026 (Ollama, LM Studio & mehr)
Die besten Browser-Erweiterungen, um lokale KI-Modelle 2026 auszuführen – von ausgefeilten Local-und-Cloud-Sidebars bis zu Open-Source-Tools für Ollama. Chatte mit jeder Seite, privat.
Ollama vs. LM Studio: Welches lokale KI-Tool passt zu dir?
Ein praktischer, nüchterner Vergleich von Ollama und LM Studio für das lokale Ausführen von KI-Modellen im Jahr 2026 – plus, wie du mit beiden mit jeder Webseite chatten kannst.