Collega un LLM locale o un'AI personalizzata al tuo browser con SurfMind
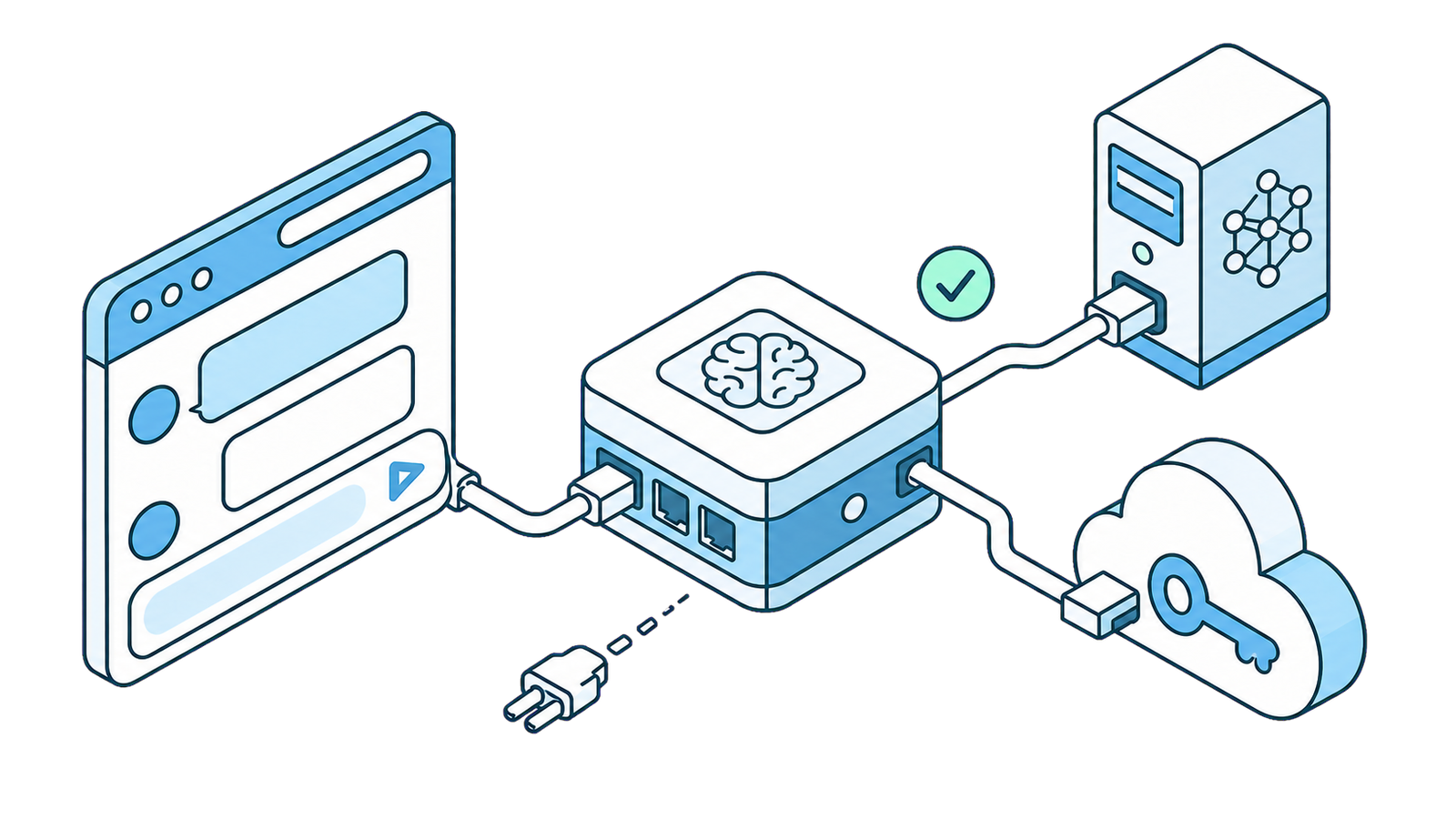
SurfMind non ti vincola a un unico insieme di modelli. Tramite la Custom Model API (API per modelli personalizzati) puoi puntarlo a un modello in esecuzione sulla tua macchina (Ollama, LM Studio, Jan, llama.cpp, vLLM) oppure a quasi qualsiasi provider AI esterno che parli la completion API di OpenAI — Poe, z.ai, Together, Groq, DeepSeek, AWS Bedrock e decine di altri.
Il rovescio della medaglia: quando non funziona al primo tentativo, spesso è colpa di un piccolo errore di configurazione. E l'errore che ricevi ("connection failed", "401", "404", "model not found") non sempre aiuta a capire cosa sia andato storto.
Questo articolo è una guida rapida di verifica e diagnosi. Scorri la checklist e controlla la tua configurazione. Se ancora non funziona, scrivici a wave@surfmind.ai.
Cerchi un provider specifico? Dai un'occhiata al nostro elenco: modelli locali (Ollama, LM Studio, Jan…) o provider AI (Poe, z.ai, Together, Groq, AWS…).
La checklist di 60 secondi
Prima di ogni altra cosa, scorri questi punti. La maggior parte dei problemi di configurazione si riduce a uno di essi:
- Il server è effettivamente in esecuzione? Per i modelli locali, il runner (Ollama, LM Studio, ecc.) deve essere avviato e avere un modello caricato.
- La porta è giusta? Ollama è
11434. LM Studio è1234. Non sono intercambiabili, ed è l'errore più comune in assoluto. - Il percorso è giusto? Il percorso nativo di Ollama è
/api/chat. Quasi tutto il resto usa/v1/chat/completions. Confonderli genera un errore. - Hai incollato l'endpoint completo, non solo la base? Il campo API URL di SurfMind vuole l'URL completo che termina con
/chat/completions(o/api/chatper Ollama), non solohttps://api.provider.com/v1. - La chiave API (e il suo header) è corretta? I runner locali di solito non richiedono alcuna chiave. I provider esterni vogliono
Authorizationcome header e la tua chiave vera come valore. - Per i modelli locali nel browser: il CORS è consentito? È l'unico passaggio aggiuntivo richiesto dalle configurazioni locali (
OLLAMA_ORIGINSoppure "Enable CORS" in LM Studio).
Se dopo tutto questo sei ancora bloccato, continua a leggere — ognuno di questi punti ha un risvolto meno ovvio su cui in molti inciampano.
Cosa va inserito in ogni campo
Quando apri la scheda Custom → Add Custom Models, ottieni il modulo "Custom Model API". Ecco esattamente cosa vuole ogni campo:
| Campo | Cosa inserire |
|---|---|
| API Name | L'etichetta che preferisci (ad es. "Groq" o "Il mio Ollama"). Clicca sulla freccia del menu a discesa per caricare un preset: Ollama e un'opzione generica compatibile con OpenAI compilano il resto al posto tuo. |
| API URL | L'endpoint chat completo, non l'URL di base. Per Ollama è http://localhost:11434/api/chat; per tutti gli altri termina con /chat/completions. Vedi Errore #1. |
| Models URL (opzionale) | L'endpoint che elenca i modelli disponibili, così SurfMind può mostrarli in un menu a discesa invece di farti digitare i nomi. Ollama: /api/tags. Compatibile con OpenAI: /v1/models. Lascialo vuoto se il provider non ha un endpoint di elenco — digiterai semplicemente tu stesso l'id del modello. |
| API Key Header | Come viene inviata la tua chiave. None = nessuna autenticazione (modelli locali). Authorization = Authorization: Bearer <key>, che usa quasi ogni provider cloud. x-api-key = x-api-key: <key>, usato dalle API in stile Anthropic e da pochi altri. |
| API Key (opzionale) | La chiave stessa — niente di più. Non digitare la parola Bearer; la aggiunge SurfMind. Lascia vuoto per i modelli locali. |
I due campi che si sbagliano più spesso sono API URL (base vs. endpoint completo) e API Key Header (quale header). Il resto della guida approfondisce proprio questi.
Errore #1: il percorso dell'API URL (la trappola /api/chat vs /v1/chat/completions)
Questo è il problema principale, e vale la pena capire perché accade.
Esistono due "dialetti" API diversi in questo mondo:
- L'API nativa di Ollama, che usa
http://localhost:11434/api/chat. - La completion API di OpenAI, che usa
.../v1/chat/completions. È quella parlata da LM Studio, vLLM, Jan, Poe, z.ai, Together, Groq — praticamente tutti gli altri.
Quindi se copi una guida di configurazione scritta per LM Studio e provi a usare quel percorso con Ollama (o viceversa), otterrai un 404 anche se il server funziona perfettamente. Il server è attivo; stai solo bussando alla porta sbagliata.
| Runner / provider | API URL corretto |
|---|---|
| Ollama (nativo) | http://localhost:11434/api/chat |
| Ollama (modalità compatibile OpenAI) | http://localhost:11434/v1/chat/completions |
| LM Studio | http://localhost:1234/v1/chat/completions |
| Tutti i compatibili con OpenAI | https://<host>/v1/chat/completions |
Buono a sapersi: Ollama in realtà parla entrambi i dialetti. L'Ollama preset in SurfMind usa il percorso nativo
/api/chat, che è la via più semplice e ti offre il rilevamento automatico dei modelli. Il percorso/v1/chat/completionsdi Ollama ti serve solo se uno strumento richiede espressamente il formato OpenAI. Con SurfMind, usa semplicemente il preset.
Errore #2: il numero di porta
Ogni runner locale usa la propria porta predefinita, e si somigliano abbastanza da invitare a un errore di battitura:
| Strumento | Porta predefinita | URL chat completo |
|---|---|---|
| Ollama | 11434 |
http://localhost:11434/api/chat |
| LM Studio | 1234 |
http://localhost:1234/v1/chat/completions |
| Jan | 1337 |
http://localhost:1337/v1/chat/completions |
llama.cpp (llama-server) |
8080 |
http://localhost:8080/v1/chat/completions |
| vLLM | 8000 |
http://localhost:8000/v1/chat/completions |
| LocalAI | 8080 |
http://localhost:8080/v1/chat/completions |
11434 vs 1234 è la classica confusione — sono facili da scambiare a colpo d'occhio, ma con una cifra sbagliata non si connette nulla. Se hai cambiato tu stesso la porta (ad es. hai avviato vLLM con --port 9000), usa la tua porta, non quella predefinita.
Una verifica veloce: apri la porta nel browser. Visitando http://localhost:11434 dovresti vedere il messaggio "Ollama is running" di Ollama. Se la pagina non si carica affatto, il server non è attivo oppure hai sbagliato porta.
Errore #3: incollare l'URL di base invece dell'endpoint
La documentazione dei provider ti fornisce quasi sempre un URL di base — qualcosa come https://api.poe.com/v1. Questo perché i loro esempi di codice usano l'SDK di OpenAI, che aggiunge /chat/completions al posto tuo dietro le quinte.
Il campo API URL di SurfMind non lo fa al posto tuo. Si aspetta l'endpoint completo. Quindi il percorso devi aggiungerlo tu:
- URL di base dalla documentazione:
https://api.poe.com/v1 - Cosa incolli in SurfMind:
https://api.poe.com/v1/chat/completions
Stesso ragionamento per il campo Models URL (usato per elencare automaticamente i modelli disponibili): prendi la base e aggiungi /models → https://api.poe.com/v1/models.
Due sviste correlate:
- Doppio
/v1. Se la base termina già con/v1, non aggiungerne un altro..../v1/v1/chat/completionsè un 404. - Slash finali.
.../chat/completions/con uno slash finale può fallire su alcuni server. Rimuovilo.
Errore #4: il Models URL non corrisponde all'API URL
Il Models URL è opzionale. È l'endpoint che SurfMind chiama per recuperare l'elenco dei modelli offerti da un provider, così da poterli mostrare in un menu a discesa invece di farti digitare i nomi. Se i tuoi modelli non compaiono nel selettore dopo aver salvato, di solito il colpevole è questo campo. Deve seguire lo stesso dialetto dell'endpoint chat:
| Dialetto | Models URL |
|---|---|
| Ollama (nativo) | http://localhost:11434/api/tags |
| Compatibile con OpenAI (tutti gli altri) | https://<host>/v1/models |
Un errore comune è mescolarli — usare /api/tags con un provider compatibile con OpenAI, oppure /v1/models con l'Ollama preset nativo. Se hai usato l'Ollama preset, questo viene compilato correttamente al posto tuo; non toccarlo.
Quando lasciarlo vuoto: alcuni provider non espongono un endpoint pubblico di elenco modelli, oppure lo bloccano. Va bene — lascia il Models URL vuoto e digita semplicemente l'id esatto del modello nel campo del modello tu stesso (vedi Errore #7). La chat funzionerà comunque; semplicemente non avrai il menu a discesa popolato automaticamente.
Errore #5: l'API Key Header (Bearer vs x-api-key)
Il menu a discesa API Key Header decide come la tua chiave viene allegata alla richiesta. Se scegli quello sbagliato otterrai un 401 Unauthorized anche con una chiave perfettamente valida. Ci sono tre opzioni:
| API Key Header | Cosa invia SurfMind | Quando usarlo |
|---|---|---|
| None | niente | I modelli locali di solito non hanno bisogno di autenticazione, ma vale la pena verificare la tua configurazione effettiva. |
| Authorization | Authorization: Bearer <your key> |
Quasi ogni provider cloud: Poe, z.ai, Together, Groq, DeepSeek, Mistral, Fireworks, xAI, AWS Bedrock. Questo è il valore predefinito per le API compatibili con OpenAI. |
| x-api-key | x-api-key: <your key> |
API in stile Anthropic e una manciata di provider che si aspettano un header con la chiave grezza invece di un token Bearer. |
Poi il campo API Key accetta solo la chiave stessa:
- Non digitare la parola
Bearer— la aggiunge SurfMind quando scegli Authorization. - Non lasciare uno spazio finale (una causa sorprendentemente comune di 401).
- Per i modelli locali, lascialo vuoto. (LM Studio è l'eccezione — vuole un qualche valore non vuoto; la sua documentazione usa
lm-studio.)
Se non sei sicuro di quale header usi un provider: il 99% dei provider compatibili con OpenAI usa Authorization. Ricorri a x-api-key solo se la documentazione del provider mostra esplicitamente un header x-api-key. Continui a ricevere un 401? Rigenera la chiave, ricontrolla la scelta dell'header e verifica che non ci sia uno spazio di troppo.
Errore #6: CORS — l'inghippo solo locale
I browser rifiutano di chiamare un server locale a meno che quel server non consenta esplicitamente le richieste dall'estensione. Questo mette in difficoltà specificamente le configurazioni locali (i provider esterni lo consentono già).
Ollama: avvialo con l'accesso da browser abilitato:
# Mac/Linux OLLAMA_ORIGINS="*" ollama serve # Windows (PowerShell) $env:OLLAMA_ORIGINS="*"; ollama serve"port 11434 already in use"? L'app Ollama in background è già in esecuzione. Chiudila prima (barra dei menu su Mac, area di notifica su Windows), poi esegui il comando qui sopra.
LM Studio: nella scheda Developer / server locale, attiva Enable CORS prima di avviare il server.
Un'ultima sottigliezza: se localhost non si connette, prova 127.0.0.1 (o viceversa). Su alcuni sistemi non si risolvono allo stesso modo.
Errore #7: il nome del modello deve corrispondere esattamente
Una volta connesso, il nome del modello che selezioni deve corrispondere a ciò che il provider si aspetta — esattamente, maiuscole comprese. È un problema che si presenta con i provider che non elencano automaticamente i modelli, o che usano una nomenclatura insolita:
- Poe usa nomi dei bot così come vengono visualizzati, tipo
Claude-Sonnet-4.6eGPT-5.4— copiali esattamente come appaiono su Poe. - z.ai usa id come
glm-4.6eglm-5. - Together AI usa id con namespace:
meta-llama/Llama-3.3-70B-Instruct-Turbo,deepseek-ai/DeepSeek-V3. - Fireworks usa un id a percorso completo:
accounts/fireworks/models/llama-v3p3-70b-instruct.
Se la connessione funziona ma ottieni "model not found", quasi sempre è un errore di battitura nel nome o un uso sbagliato delle maiuscole. Quando SurfMind può elencare i modelli automaticamente tramite il Models URL, scegli dall'elenco invece di digitare a mano.
Riferimento rapido: modelli locali
Tutti questi girano sulla tua macchina. Apri la scheda Custom di SurfMind → Add Custom Models, scegli il preset corrispondente (Ollama ha il suo; gli altri usano il preset generico OpenAI-compatible) e imposta API Key Header su None. I nomi dei provider rimandano alla documentazione di configurazione di ciascuno strumento.
- API URL:
http://localhost:11434/api/chat - Models URL:
http://localhost:11434/api/tags - API key: nessuna
- API URL:
http://localhost:1234/v1/chat/completions - Models URL:
http://localhost:1234/v1/models - API key: qualsiasi valore non vuoto (ad es.
lm-studio)
- API URL:
http://localhost:1337/v1/chat/completions - Models URL:
http://localhost:1337/v1/models - API key: nessuna (oppure la tua chiave Jan)
- API URL:
http://localhost:8080/v1/chat/completions - Models URL:
http://localhost:8080/v1/models - API key: nessuna (a meno che tu non l'abbia avviato con
--api-key)
- API URL:
http://localhost:8000/v1/chat/completions - Models URL:
http://localhost:8000/v1/models - API key: la tua
--api-keyse ne hai impostata una
- API URL:
http://localhost:8080/v1/chat/completions - Models URL:
http://localhost:8080/v1/models - API key: nessuna
Non dimenticare il passaggio CORS (Errore #6) per ognuno di questi. Per Ollama in particolare, la guida completa con screenshot si trova nella nostra guida a Ollama, e se stai decidendo tra i primi due, vedi Ollama vs LM Studio.
Riferimento rapido: provider AI popolari
Tutti questi provider cloud parlano l'API compatibile con OpenAI. Usa il preset generico OpenAI-compatible, imposta l'API Key Header su Authorization (usano tutti token Bearer) e incolla la tua chiave. I nomi dei provider rimandano alla documentazione API di ciascun provider.
Poe — una sola chiave per centinaia di modelli (Claude, GPT, Gemini, Llama…), addebitati sui punti del tuo abbonamento Poe. I nomi dei modelli sono i nomi dei bot così come vengono visualizzati — copiali esattamente come appaiono su Poe (ad es. Claude-Sonnet-4.6, GPT-5.4). Chiave da poe.com → Settings → API key.
- API URL:
https://api.poe.com/v1/chat/completions - Models URL:
https://api.poe.com/v1/models
CanopyWave — provider GPU-cloud che serve modelli aperti (Kimi, DeepSeek, Llama, Qwen). Chiave dalla dashboard di CanopyWave.
- API URL:
https://inference.canopywave.io/v1/chat/completions - Models URL:
https://inference.canopywave.io/v1/models
z.ai (GLM) — i modelli GLM di Zhipu (glm-4.6, glm-5). Attenzione: z.ai pubblica anche un endpoint Coding Plan separato (https://api.z.ai/api/coding/paas/v4) e un endpoint PaaS (https://api.z.ai/api/paas/v4) — usa quello compatibile con OpenAI qui sotto e non aggiungere un /v1 extra.
- API URL:
https://api.z.ai/api/openai/v1/chat/completions - Models URL:
https://api.z.ai/api/openai/v1/models
Together AI — ampio catalogo di modelli aperti. Gli id dei modelli sono lunghi (meta-llama/Llama-3.3-70B-Instruct-Turbo) — copiali esattamente dalla pagina dei modelli di Together.
- API URL:
https://api.together.xyz/v1/chat/completions - Models URL:
https://api.together.xyz/v1/models
Groq — inferenza estremamente veloce. Inghippo: il percorso è /openai/v1, non solo /v1.
- API URL:
https://api.groq.com/openai/v1/chat/completions - Models URL:
https://api.groq.com/openai/v1/models
DeepSeek — i modelli attuali sono deepseek-v4-flash e deepseek-v4-pro (i vecchi alias deepseek-chat / deepseek-reasoner stanno per essere ritirati — controlla la documentazione di DeepSeek per gli ultimi aggiornamenti). Il /v1 è opzionale; DeepSeek accetta l'URL con o senza.
- API URL:
https://api.deepseek.com/v1/chat/completions - Models URL:
https://api.deepseek.com/v1/models
Mistral — mistral-large-latest, mistral-small-latest, ecc. Standard compatibile con OpenAI.
- API URL:
https://api.mistral.ai/v1/chat/completions - Models URL:
https://api.mistral.ai/v1/models
Fireworks AI — inghippo: il percorso è /inference/v1, non /v1. Gli id dei modelli hanno l'aspetto accounts/fireworks/models/llama-v3p3-70b-instruct.
- API URL:
https://api.fireworks.ai/inference/v1/chat/completions - Models URL:
https://api.fireworks.ai/inference/v1/models
xAI (Grok) — modelli Grok (grok-4, ecc.). Standard compatibile con OpenAI.
- API URL:
https://api.x.ai/v1/chat/completions - Models URL:
https://api.x.ai/v1/models
AWS Bedrock — Bedrock ora ha un endpoint compatibile con OpenAI, ma con due inghippi: l'host è specifico per regione (ad es. us-west-2) e il percorso è /openai/v1. Devi usare una Bedrock API key (un token bearer che generi nella console) — non le tue normali chiavi di accesso AWS/SigV4. Gli id dei modelli hanno l'aspetto openai.gpt-oss-120b-1:0.
- API URL:
https://bedrock-runtime.<region>.amazonaws.com/openai/v1/chat/completions - Models URL: lascia vuoto — inserisci l'id del modello in seguito
Ancora non si connette? Triage finale
Procedi lungo questo elenco:
- Apri l'host dell'API URL nel tuo browser. Server locale che non si carica → non è in esecuzione, oppure la porta è sbagliata.
- Rileggi il percorso. Ollama →
/api/chat. Tutti gli altri →/v1/chat/completions(o il percorso speciale del provider dalla tabella). - Verifica di aver incollato l'endpoint completo, non la base, e che non ci sia un doppio
/v1o uno slash finale. - 401? È la chiave o l'header. Header =
Authorization, chiave senza spazi, senza prefissoBearer. - 404 "model not found"? La connessione va bene — correggi il nome del modello (maiuscole esatte).
- Modello locale, browser bloccato? Abilita il CORS (
OLLAMA_ORIGINS="*"o l'interruttore di LM Studio) e prova127.0.0.1vslocalhost.
Questa sequenza risolve la stragrande maggioranza delle configurazioni.
Hai ancora bisogno di aiuto?
Se hai seguito tutta la checklist e il tuo provider continua a non connettersi, scrivici una email all'indirizzo wave@surfmind.ai indicando il provider che stai provando e l'errore che vedi. Ti aiuteremo a connetterlo.
Connesso? Apri SurfMind sulla prossima pagina che stavi per leggere e metti al lavoro il tuo modello.
Post recenti
Vedi tutto
IA privata in Firefox: esegui modelli locali con zero telemetria
Aggiungi a Firefox un assistente IA privato che gira su modelli locali, così il contenuto delle tue pagine non lascia mai la tua macchina. Niente telemetria, niente cloud, nessun compromesso.

Le migliori estensioni per browser per modelli IA locali nel 2026 (Ollama, LM Studio e altri)
Le migliori estensioni per browser per eseguire modelli IA locali nel 2026, dalle sidebar curate local+cloud agli strumenti Ollama open source. Chatta con qualsiasi pagina, in privato.
Ollama vs LM Studio: quale strumento di IA locale fa per te?
Un confronto pratico e senza esagerazioni tra Ollama e LM Studio per eseguire modelli IA in locale nel 2026, più come usare l'uno o l'altro per chattare con qualsiasi pagina web.