Подключите локальную LLM или собственный ИИ к браузеру с помощью SurfMind
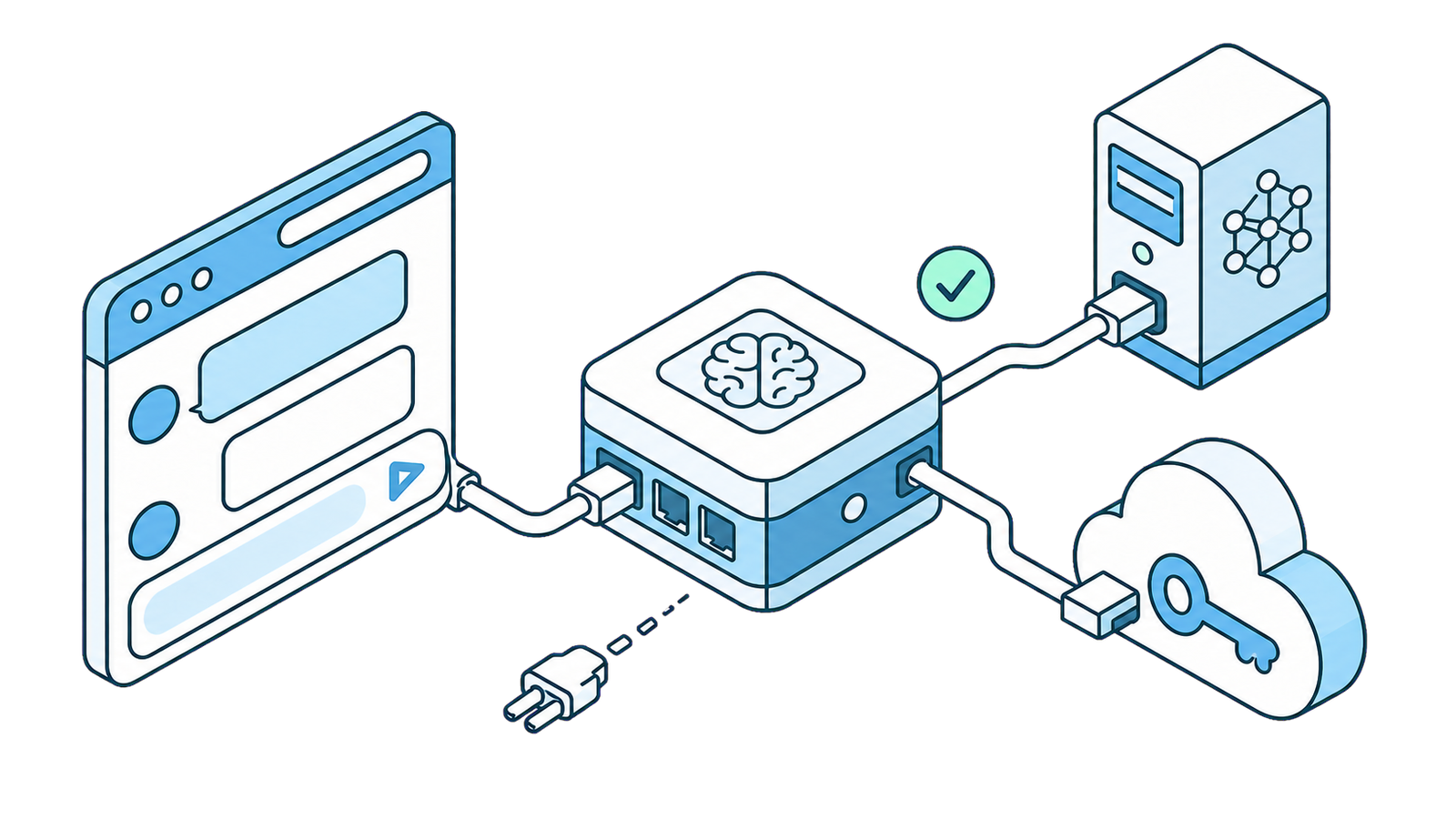
SurfMind не привязывает вас к одному набору моделей. Через Custom Model API (API для собственных моделей) вы можете подключить модель, запущенную на вашей машине (Ollama, LM Studio, Jan, llama.cpp, vLLM), или практически любого внешнего AI-провайдера, который понимает completion API OpenAI — Poe, z.ai, Together, Groq, DeepSeek, AWS Bedrock и десятки других.
Загвоздка в том, что если с первого раза не заработало, причиной обычно оказывается небольшая ошибка в конфигурации. А сообщение, которое возвращается в ответ («connection failed», «401», «404», «model not found»), не всегда подсказывает, в чём дело.
Этот пост — краткое руководство для быстрой проверки и самостоятельного решения проблем. Пробегитесь по чек-листу и проверьте свою настройку. Если всё равно не работает, напишите нам на wave@surfmind.ai.
Ищете конкретного провайдера? Загляните в наш список: локальные модели (Ollama, LM Studio, Jan…) или AI-провайдеры (Poe, z.ai, Together, Groq, AWS…).
Чек-лист на 60 секунд
Прежде всего пройдитесь по этим пунктам. Большинство проблем с настройкой сводятся к одному из них:
- Сервер действительно запущен? Для локальных моделей сам раннер (Ollama, LM Studio и т. д.) должен быть запущен и иметь загруженную модель.
- Правильный ли порт? У Ollama это
11434. У LM Studio —1234. Они не взаимозаменяемы, и это самая распространённая ошибка. - Правильный ли путь? Нативный путь Ollama —
/api/chat. Почти у всех остальных это/v1/chat/completions. Перепутаете их — получите ошибку. - Вы вставили полный эндпоинт, а не только базовый адрес? Поле API URL в SurfMind ожидает полный URL, оканчивающийся на
/chat/completions(или/api/chatдля Ollama), а не простоhttps://api.provider.com/v1. - Правильный ли API-ключ (и его заголовок)? Локальным раннерам обычно ключ не нужен. Внешним провайдерам нужен заголовок
Authorizationи ваш настоящий ключ в качестве значения. - Для локальных моделей в браузере: разрешён ли CORS? Это тот единственный дополнительный шаг, который требуется локальным настройкам (
OLLAMA_ORIGINSили «Enable CORS» в LM Studio).
Если после этого всё равно не вышло — читайте дальше: у каждого из этих пунктов есть менее очевидный вариант, на котором люди и спотыкаются.
Что вводить в каждое поле
Когда вы открываете вкладку Custom → Add Custom Models, появляется форма «Custom Model API». Вот что именно нужно вводить в каждое поле:
| Поле | Что вводить |
|---|---|
| API Name | Любое название на ваш вкус (например, «Groq» или «My Ollama»). Нажмите на стрелку выпадающего списка, чтобы загрузить пресет — Ollama и универсальный вариант, совместимый с OpenAI, заполнят остальное за вас. |
| API URL | Полный эндпоинт чата, а не базовый URL. Для Ollama это http://localhost:11434/api/chat; для всех остальных он оканчивается на /chat/completions. См. Ошибку №1. |
| Models URL (опционально) | Эндпоинт, который перечисляет доступные модели, чтобы SurfMind мог показать их в выпадающем списке вместо того, чтобы вы вводили имена вручную. Ollama: /api/tags. Совместимые с OpenAI: /v1/models. Оставьте пустым, если у провайдера нет эндпоинта списка — тогда вы просто введёте id модели сами. |
| API Key Header | Как передаётся ваш ключ. None = без авторизации (локальные модели). Authorization = Authorization: Bearer <key>, который использует почти каждый облачный провайдер. x-api-key = x-api-key: <key>, его используют API в стиле Anthropic и ещё некоторые провайдеры. |
| API Key (опционально) | Сам ключ — и ничего больше. Не вводите слово Bearer; SurfMind добавит его сам. Для локальных моделей оставьте пустым. |
Чаще всего ошибаются в двух полях: API URL (базовый адрес или полный эндпоинт) и API Key Header (какой именно заголовок). Остальная часть руководства подробно разбирает именно их.
Ошибка №1: путь в API URL (ловушка /api/chat против /v1/chat/completions)
Это самая частая ошибка, и стоит понять, почему она возникает.
В этом мире есть два разных «диалекта» API:
- Нативный API Ollama, который использует
http://localhost:11434/api/chat. - Completion API OpenAI, который использует
.../v1/chat/completions. На нём говорят LM Studio, vLLM, Jan, Poe, z.ai, Together, Groq — в общем, все остальные.
Поэтому если вы скопируете гайд по настройке, написанный для LM Studio, и попробуете использовать этот путь с Ollama (или наоборот), вы получите 404, хотя сервер работает безупречно. Сервер запущен; вы просто стучите не в ту дверь.
| Раннер / провайдер | Правильный API URL |
|---|---|
| Ollama (нативный) | http://localhost:11434/api/chat |
| Ollama (режим, совместимый с OpenAI) | http://localhost:11434/v1/chat/completions |
| LM Studio | http://localhost:1234/v1/chat/completions |
| Все совместимые с OpenAI | https://<host>/v1/chat/completions |
Полезно знать: Ollama на самом деле говорит на обоих диалектах. Ollama preset в SurfMind использует нативный путь
/api/chat, который является самым простым маршрутом и даёт автоматическое обнаружение моделей. Путь/v1/chat/completionsдля Ollama нужен только тогда, когда какой-то инструмент специально требует формат OpenAI. Для SurfMind просто используйте пресет.
Ошибка №2: номер порта
Каждый локальный раннер выбирает свой порт по умолчанию, и они выглядят достаточно похоже, чтобы промахнуться при наборе:
| Инструмент | Порт по умолчанию | Полный URL чата |
|---|---|---|
| Ollama | 11434 |
http://localhost:11434/api/chat |
| LM Studio | 1234 |
http://localhost:1234/v1/chat/completions |
| Jan | 1337 |
http://localhost:1337/v1/chat/completions |
llama.cpp (llama-server) |
8080 |
http://localhost:8080/v1/chat/completions |
| vLLM | 8000 |
http://localhost:8000/v1/chat/completions |
| LocalAI | 8080 |
http://localhost:8080/v1/chat/completions |
11434 против 1234 — классическая путаница: их легко спутать на первый взгляд, но одна неверная цифра — и ничего не подключается. Если вы сами поменяли порт (например, запустили vLLM с --port 9000), используйте свой порт, а не значение по умолчанию.
Быстрая проверка: откройте порт в браузере. При переходе на http://localhost:11434 должно появиться сообщение Ollama «Ollama is running». Если страница вообще не загружается — сервер не запущен или у вас неверный порт.
Ошибка №3: вставка базового URL вместо эндпоинта
Документация провайдеров почти всегда даёт вам базовый URL — что-то вроде https://api.poe.com/v1. Это потому, что их примеры кода используют OpenAI SDK, который под капотом сам дописывает /chat/completions.
Поле API URL в SurfMind за вас этого не делает. Оно ожидает полный эндпоинт. Поэтому путь нужно добавить самостоятельно:
- Базовый URL из документации:
https://api.poe.com/v1 - Что вы вставляете в SurfMind:
https://api.poe.com/v1/chat/completions
То же самое касается поля Models URL (через него автоматически подтягивается список доступных моделей): возьмите базовый адрес и добавьте /models → https://api.poe.com/v1/models.
Две связанные оплошности:
- Двойной
/v1. Если базовый адрес уже оканчивается на/v1, не добавляйте ещё один..../v1/v1/chat/completions— это 404. - Завершающие слеши.
.../chat/completions/с завершающим слешем может не работать на некоторых серверах. Уберите его.
Ошибка №4: Models URL не соответствует API URL
Models URL опционален. Это эндпоинт, который SurfMind вызывает, чтобы получить список моделей, предлагаемых провайдером, и показать их в выпадающем списке вместо того, чтобы вы вводили имена вручную. Если после сохранения ваши модели не появляются в селекторе, виновато обычно именно это поле. Оно должно следовать тому же диалекту, что и эндпоинт чата:
| Диалект | Models URL |
|---|---|
| Ollama (нативный) | http://localhost:11434/api/tags |
| Совместимый с OpenAI (все остальные) | https://<host>/v1/models |
Распространённая ошибка — смешивать их: использовать /api/tags с провайдером, совместимым с OpenAI, или /v1/models с нативным пресетом Ollama. Если вы использовали Ollama preset, это поле заполнено за вас правильно; не трогайте его.
Когда оставлять пустым: некоторые провайдеры не предоставляют публичный эндпоинт списка моделей или блокируют его. Это нормально — оставьте Models URL пустым и просто введите точный id модели в поле модели самостоятельно (см. Ошибку №7). Чат всё равно будет работать; вы просто не получите автоматически заполненный выпадающий список.
Ошибка №5: API Key Header (Bearer против x-api-key)
Выпадающий список API Key Header определяет, как ваш ключ добавляется к запросу. Выберете не тот — и получите 401 Unauthorized даже с совершенно правильным ключом. Есть три варианта:
| API Key Header | Что отправляет SurfMind | Когда использовать |
|---|---|---|
| None | ничего | Локальным моделям авторизация обычно не нужна, но это стоит проверить в вашей конкретной настройке. |
| Authorization | Authorization: Bearer <your key> |
Почти каждый облачный провайдер: Poe, z.ai, Together, Groq, DeepSeek, Mistral, Fireworks, xAI, AWS Bedrock. Это значение по умолчанию для API, совместимых с OpenAI. |
| x-api-key | x-api-key: <your key> |
API в стиле Anthropic и небольшое число провайдеров, которые ожидают «сырой» заголовок ключа вместо Bearer-токена. |
Затем поле API Key принимает только сам ключ:
- Не вводите слово
Bearer— SurfMind добавит его, когда вы выберете Authorization. - Не оставляйте завершающий пробел (на удивление частая причина 401).
- Для локальных моделей оставьте поле пустым. (LM Studio — исключение: ему нужно какое-то непустое значение; в его собственной документации используется
lm-studio.)
Если не уверены, какой заголовок использует провайдер: 99% провайдеров, совместимых с OpenAI, используют Authorization. Прибегайте к x-api-key только если в документации провайдера явно показан заголовок x-api-key. Всё ещё получаете 401? Сгенерируйте ключ заново, перепроверьте выбор заголовка и убедитесь, что нет лишнего пробела.
Ошибка №6: CORS — подвох, актуальный только для локальных настроек
Браузеры отказываются обращаться к локальному серверу, пока тот явно не разрешит запросы от расширения. С этим сталкиваются именно при локальной настройке (внешние провайдеры запросы уже разрешают).
Ollama: запускайте его с включённым доступом из браузера:
# Mac/Linux OLLAMA_ORIGINS="*" ollama serve # Windows (PowerShell) $env:OLLAMA_ORIGINS="*"; ollama serve«port 11434 already in use»? Фоновое приложение Ollama уже запущено. Сначала закройте его (строка меню на Mac, системный трей на Windows), а затем выполните команду выше.
LM Studio: на вкладке Developer / локального сервера включите переключатель Enable CORS перед запуском сервера.
Ещё одна тонкость: если localhost не подключается, попробуйте вместо него 127.0.0.1 (или наоборот). На некоторых системах они разрешаются по-разному.
Ошибка №7: имя модели должно совпадать точно
После того как вы подключились, выбранное имя модели должно совпадать с тем, что ожидает провайдер — в точности, включая регистр. На этом обычно спотыкаются с провайдерами, которые не выводят список моделей автоматически или используют необычные имена:
- Poe использует отображаемые имена ботов, например
Claude-Sonnet-4.6иGPT-5.4— копируйте их в точности так, как они показаны на Poe. - z.ai использует id вроде
glm-4.6иglm-5. - Together AI использует id с префиксом пространства имён:
meta-llama/Llama-3.3-70B-Instruct-Turbo,deepseek-ai/DeepSeek-V3. - Fireworks использует id в виде полного пути:
accounts/fireworks/models/llama-v3p3-70b-instruct.
Если соединение работает, но вы получаете «model not found», почти всегда дело в опечатке в имени или неверном регистре. Когда SurfMind может автоматически вывести список моделей через Models URL, выбирайте из списка, а не вводите вручную.
Краткий справочник: локальные модели
Все они работают на вашей собственной машине. Откройте вкладку Custom в SurfMind → Add Custom Models, выберите подходящий пресет (у Ollama он свой; остальные используют универсальный пресет OpenAI-compatible) и установите API Key Header в None. Имена провайдеров ведут на документацию по настройке каждого инструмента.
- API URL:
http://localhost:11434/api/chat - Models URL:
http://localhost:11434/api/tags - API-ключ: не нужен
- API URL:
http://localhost:1234/v1/chat/completions - Models URL:
http://localhost:1234/v1/models - API-ключ: любое непустое значение (например,
lm-studio)
- API URL:
http://localhost:1337/v1/chat/completions - Models URL:
http://localhost:1337/v1/models - API-ключ: не нужен (или ваш ключ Jan)
- API URL:
http://localhost:8080/v1/chat/completions - Models URL:
http://localhost:8080/v1/models - API-ключ: не нужен (если вы не запустили его с
--api-key)
- API URL:
http://localhost:8000/v1/chat/completions - Models URL:
http://localhost:8000/v1/models - API-ключ: ваш
--api-key, если вы его задали
- API URL:
http://localhost:8080/v1/chat/completions - Models URL:
http://localhost:8080/v1/models - API-ключ: не нужен
Не забудьте про шаг с CORS (Ошибка №6) для любого из них. Для Ollama в частности полное пошаговое руководство со скриншотами есть в нашем гайде по Ollama, а если вы выбираете между первыми двумя, см. Ollama против LM Studio.
Краткий справочник: популярные AI-провайдеры
Все эти облачные провайдеры говорят на API, совместимом с OpenAI. Используйте универсальный пресет OpenAI-compatible, установите API Key Header в Authorization (все они используют Bearer-токены) и вставьте свой ключ. Имена провайдеров ведут на API-документацию каждого провайдера.
Poe — один ключ для сотен моделей (Claude, GPT, Gemini, Llama…), оплата за счёт баллов вашей подписки Poe. Имена моделей — это отображаемые имена ботов, копируйте их в точности так, как показано на Poe (например, Claude-Sonnet-4.6, GPT-5.4). Ключ из poe.com → Settings → API key.
- API URL:
https://api.poe.com/v1/chat/completions - Models URL:
https://api.poe.com/v1/models
CanopyWave — провайдер GPU-облака, обслуживающий открытые модели (Kimi, DeepSeek, Llama, Qwen). Ключ из панели управления CanopyWave.
- API URL:
https://inference.canopywave.io/v1/chat/completions - Models URL:
https://inference.canopywave.io/v1/models
z.ai (GLM) — модели GLM от Zhipu (glm-4.6, glm-5). Внимание: z.ai также публикует отдельный эндпоинт Coding Plan (https://api.z.ai/api/coding/paas/v4) и эндпоинт PaaS (https://api.z.ai/api/paas/v4) — используйте совместимый с OpenAI вариант ниже и не добавляйте лишний /v1.
- API URL:
https://api.z.ai/api/openai/v1/chat/completions - Models URL:
https://api.z.ai/api/openai/v1/models
Together AI — большой каталог открытых моделей. Id моделей длинные (meta-llama/Llama-3.3-70B-Instruct-Turbo) — копируйте их в точности со страницы модели Together.
- API URL:
https://api.together.xyz/v1/chat/completions - Models URL:
https://api.together.xyz/v1/models
Groq — чрезвычайно быстрый инференс. Подвох: путь — это /openai/v1, а не просто /v1.
- API URL:
https://api.groq.com/openai/v1/chat/completions - Models URL:
https://api.groq.com/openai/v1/models
DeepSeek — актуальные модели — deepseek-v4-flash и deepseek-v4-pro (старые алиасы deepseek-chat / deepseek-reasoner постепенно выводятся из обращения — актуальный список смотрите в документации DeepSeek). /v1 необязателен; DeepSeek принимает URL как с ним, так и без него.
- API URL:
https://api.deepseek.com/v1/chat/completions - Models URL:
https://api.deepseek.com/v1/models
Mistral — mistral-large-latest, mistral-small-latest и т. д. Стандартный, совместимый с OpenAI.
- API URL:
https://api.mistral.ai/v1/chat/completions - Models URL:
https://api.mistral.ai/v1/models
Fireworks AI — подвох: путь — это /inference/v1, а не /v1. Id моделей выглядят как accounts/fireworks/models/llama-v3p3-70b-instruct.
- API URL:
https://api.fireworks.ai/inference/v1/chat/completions - Models URL:
https://api.fireworks.ai/inference/v1/models
xAI (Grok) — модели Grok (grok-4 и др.). Стандартный, совместимый с OpenAI.
- API URL:
https://api.x.ai/v1/chat/completions - Models URL:
https://api.x.ai/v1/models
AWS Bedrock — у Bedrock теперь есть эндпоинт, совместимый с OpenAI, но с двумя подвохами: хост зависит от региона (например, us-west-2), а путь — это /openai/v1. Вы должны использовать Bedrock API key (bearer-токен, который вы генерируете в консоли) — а не ваши обычные ключи доступа AWS / SigV4. Id моделей выглядят как openai.gpt-oss-120b-1:0.
- API URL:
https://bedrock-runtime.<region>.amazonaws.com/openai/v1/chat/completions - Models URL: оставьте пустым — введите id модели позже
Всё ещё не подключается? Финальная диагностика
Двигайтесь по этому списку сверху вниз:
- Откройте хост из API URL в браузере. Локальный сервер не загружается → он не запущен или неверный порт.
- Перечитайте путь. Ollama →
/api/chat. Все остальные →/v1/chat/completions(или особый путь провайдера из таблицы). - Убедитесь, что вы вставили полный эндпоинт, а не базовый адрес, и что нет двойного
/v1или завершающего слеша. - 401? Дело в ключе или заголовке. Заголовок =
Authorization, ключ без пробелов, без префиксаBearer. - 404 «model not found»? С соединением всё в порядке — исправьте имя модели (точный регистр).
- Локальная модель, браузер блокирует? Включите CORS (
OLLAMA_ORIGINS="*"или переключатель LM Studio) и попробуйте127.0.0.1противlocalhost.
Эта последовательность решает подавляющее большинство случаев настройки.
Всё ещё нужна помощь?
Если вы прошли весь чек-лист, а ваш провайдер всё равно не подключается, напишите нам на wave@surfmind.ai, указав провайдера, которого вы пытаетесь подключить, и ошибку, которую видите. Мы поможем вам наладить подключение.
Подключили? Откройте SurfMind на следующей странице, которую собирались прочитать, и пустите свою модель в дело.
Последние публикации
Смотреть все
Приватный ИИ в Firefox: запускайте локальные модели с нулевой телеметрией
Добавьте в Firefox приватного ИИ-помощника, работающего на локальных моделях, чтобы содержимое ваших страниц никогда не покидало компьютер. Без телеметрии, без облака, без компромиссов.

Лучшие браузерные расширения для локальных ИИ-моделей в 2026 году (Ollama, LM Studio и другие)
Лучшие браузерные расширения для запуска локальных ИИ-моделей в 2026 году — от отполированных локально-облачных боковых панелей до инструментов Ollama с открытым исходным кодом. Общайтесь с любой страницей приватно.
Ollama против LM Studio: какой инструмент для локального ИИ подойдет именно вам?
Практичное сравнение Ollama и LM Studio без лишнего хайпа: как запускать ИИ-модели локально в 2026 году и как с помощью любого из них общаться с любой веб-страницей.