اربط نموذج LLM محلي أو ذكاءً اصطناعيًا مخصصًا بمتصفحك عبر SurfMind
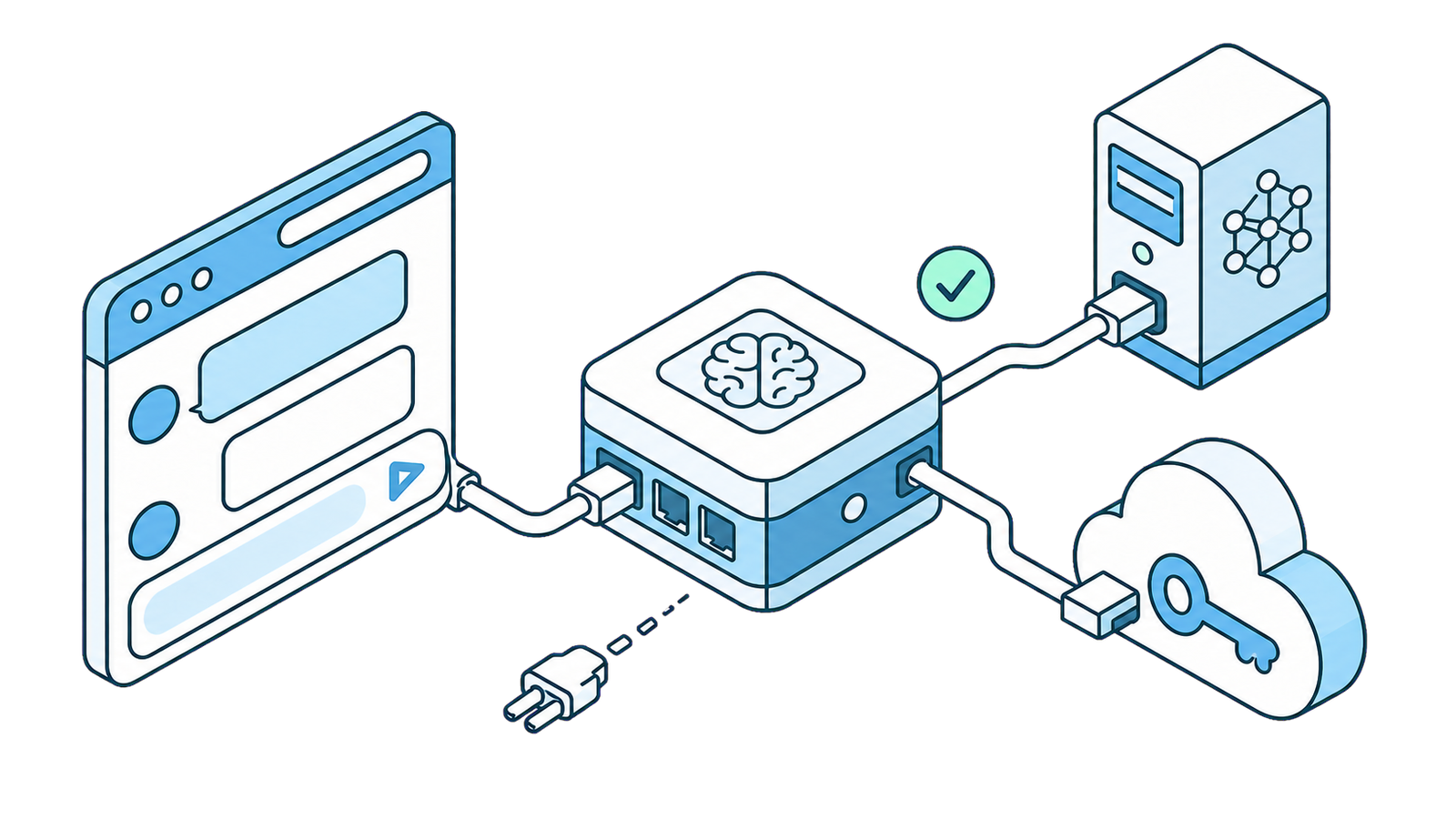
لا يحصرك SurfMind في مجموعة واحدة من النماذج. فمن خلال Custom Model API (واجهة النماذج المخصصة)، يمكنك توجيهه إلى نموذج يعمل على جهازك الخاص (Ollama، LM Studio، Jan، llama.cpp، vLLM) أو إلى أي مزوّد ذكاء اصطناعي خارجي تقريبًا يدعم واجهة الإكمال الخاصة بـ OpenAI — مثل Poe وz.ai وTogether وGroq وDeepSeek وAWS Bedrock وعشرات غيرها.
لكنّ العقبة هي: حين لا ينجح الأمر من المحاولة الأولى، قد يكون السبب خطأ إعدادٍ بسيطًا. ورسالة الخطأ التي تظهر لك ("connection failed" أو "401" أو "404" أو "model not found") قد تكون محيّرة.
هذه التدوينة دليل سريع للفحص والمساعدة الذاتية. اطّلع سريعًا على قائمة التحقق وتأكّد من إعدادك. وإن لم ينجح الأمر بعد، راسلنا عبر البريد الإلكتروني على wave@surfmind.ai.
تبحث عن مزوّد بعينه؟ اطّلع على قائمتنا: النماذج المحلية (Ollama، LM Studio، Jan…) أو مزوّدو الذكاء الاصطناعي (Poe، z.ai، Together، Groq، AWS…).
قائمة التحقق في 60 ثانية
قبل أي شيء آخر، راجع هذه النقاط. فمعظم مشكلات الإعداد تعود إلى إحداها:
- هل الخادم يعمل فعلًا؟ بالنسبة إلى النماذج المحلية، يجب أن يكون المشغّل (Ollama، LM Studio، وغيرهما) قد بدأ و حمّل نموذجًا.
- هل المنفذ صحيح؟ منفذ Ollama هو
11434، ومنفذ LM Studio هو1234. وهما غير قابلين للتبادل، وهذا هو الخطأ الأكثر شيوعًا على الإطلاق. - هل المسار صحيح؟ المسار الأصلي لـ Ollama هو
/api/chat. وكل شيء آخر تقريبًا يستخدم/v1/chat/completions. والخلط بينهما يعطيك خطأً. - هل لصقت نقطة النهاية الكاملة، لا الأساس فقط؟ يتطلب حقل API URL في SurfMind الرابط الكامل المنتهي بـ
/chat/completions(أو/api/chatلـ Ollama)، وليس فقطhttps://api.provider.com/v1. - هل مفتاح الـ API (وترويسته) صحيح؟ المشغّلات المحلية لا تحتاج عادةً إلى مفتاح. أما المزوّدون الخارجيون فيحتاجون إلى
Authorizationكترويسة، ومفتاحك الحقيقي كقيمة. - بالنسبة إلى النماذج المحلية في المتصفح: هل CORS مسموح به؟ هذه هي الخطوة الإضافية الوحيدة التي تحتاجها الإعدادات المحلية (
OLLAMA_ORIGINS، أو "Enable CORS" في LM Studio).
إن بقيت عالقًا بعد ذلك، فتابع القراءة — فلكلٍّ من هذه النقاط جانب دقيق يقع فيه كثيرون دون أن ينتبهوا.
ما يوضع في كل حقل
عند فتح تبويب Custom ← Add Custom Models، يظهر لك نموذج "Custom Model API". وإليك بالضبط ما يتطلبه كل حقل:
| الحقل | ما تُدخله |
|---|---|
| API Name | أي اسم تشاء (مثل "Groq" أو "My Ollama"). انقر سهم القائمة المنسدلة لتحميل preset (إعداد جاهز) — يملأ كلٌّ من Ollama والخيار العام المتوافق مع OpenAI بقية الحقول نيابةً عنك. |
| API URL | نقطة نهاية الدردشة الكاملة، لا الرابط الأساسي. بالنسبة إلى Ollama يكون http://localhost:11434/api/chat؛ وبالنسبة إلى الجميع ينتهي بـ /chat/completions. راجع الخطأ رقم 1. |
| Models URL (اختياري) | نقطة النهاية التي تسرد النماذج المتاحة، بحيث يستطيع SurfMind عرضها في قائمة منسدلة بدلًا من إجبارك على كتابة الأسماء. Ollama: /api/tags. المتوافق مع OpenAI: /v1/models. اترك الحقل فارغًا إن لم يكن لدى المزوّد نقطة نهاية للسرد — وستكتب معرّف النموذج بنفسك حينئذٍ. |
| API Key Header | كيفية إرسال مفتاحك. None = لا مصادقة (النماذج المحلية). Authorization = Authorization: Bearer <key>، وهو ما يستخدمه كل مزوّد سحابي تقريبًا. x-api-key = x-api-key: <key>، وتستخدمه الواجهات على نمط Anthropic وقلّة غيرها. |
| API Key (اختياري) | المفتاح نفسه فحسب — لا أكثر. لا تكتب كلمة Bearer؛ فـ SurfMind يضيفها. اتركه فارغًا للنماذج المحلية. |
الحقلان اللذان يخطئ فيهما الناس هما API URL (الأساس مقابل نقطة النهاية الكاملة) وAPI Key Header (أي ترويسة). وبقية هذا الدليل تتعمّق في هذين الحقلين.
الخطأ رقم 1: مسار الـ API URL (فخّ /api/chat مقابل /v1/chat/completions)
هذا هو الخطأ الأكبر، ويستحق أن تفهم لماذا يحدث.
هناك "لهجتان" مختلفتان للواجهات في هذا العالم:
- الواجهة الأصلية لـ Ollama، التي تستخدم
http://localhost:11434/api/chat. - واجهة الإكمال الخاصة بـ OpenAI، التي تستخدم
.../v1/chat/completions. وهذا ما تتحدث به LM Studio وvLLM وJan وPoe وz.ai وTogether وGroq — أي الجميع تقريبًا.
لذا إن نسخت دليل إعداد مكتوبًا لـ LM Studio وحاولت استخدام ذلك المسار مع Ollama (أو العكس)، فستحصل على خطأ 404 رغم أن الخادم يعمل بكفاءة تامة. الخادم يعمل؛ لكنك تطرق الباب الخطأ فحسب.
| المشغّل / المزوّد | الـ API URL الصحيح |
|---|---|
| Ollama (الأصلي) | http://localhost:11434/api/chat |
| Ollama (الوضع المتوافق مع OpenAI) | http://localhost:11434/v1/chat/completions |
| LM Studio | http://localhost:1234/v1/chat/completions |
| كل ما هو متوافق مع OpenAI | https://<host>/v1/chat/completions |
جدير بالمعرفة: يتحدث Ollama في الواقع كلتا اللهجتين. ويستخدم Ollama preset في SurfMind المسار الأصلي
/api/chat، وهو أبسط طريق ويمنحك اكتشافًا تلقائيًا للنماذج. ولن تحتاج إلى مسار/v1/chat/completionsالخاص بـ Ollama إلا إذا تطلّبت أداةٌ ما صيغة OpenAI تحديدًا. أما في SurfMind، فاكتفِ بالإعداد الجاهز (preset).
الخطأ رقم 2: رقم المنفذ
يختار كل مشغّل محلي منفذه الافتراضي الخاص، وهي متشابهة بدرجة تجعل الخطأ في كتابتها أمرًا واردًا:
| الأداة | المنفذ الافتراضي | رابط الدردشة الكامل |
|---|---|---|
| Ollama | 11434 |
http://localhost:11434/api/chat |
| LM Studio | 1234 |
http://localhost:1234/v1/chat/completions |
| Jan | 1337 |
http://localhost:1337/v1/chat/completions |
llama.cpp (llama-server) |
8080 |
http://localhost:8080/v1/chat/completions |
| vLLM | 8000 |
http://localhost:8000/v1/chat/completions |
| LocalAI | 8080 |
http://localhost:8080/v1/chat/completions |
الخلط بين 11434 و1234 هو الالتباس الكلاسيكي — فمن السهل الخلط بينهما لأول وهلة، لكن رقمًا واحدًا خاطئًا يعني أن لا شيء سيتصل. وإن غيّرت المنفذ بنفسك (مثل تشغيل vLLM عبر --port 9000)، فاستخدم منفذك أنت، لا المنفذ الافتراضي.
فحص سريع للتأكد: افتح المنفذ في متصفحك. فزيارة http://localhost:11434 ينبغي أن تُظهر رسالة "Ollama is running" الخاصة بـ Ollama. وإن لم تُحمَّل الصفحة إطلاقًا، فالخادم لا يعمل أو أن المنفذ خاطئ.
الخطأ رقم 3: لصق الرابط الأساسي بدلًا من نقطة النهاية
تمنحك وثائق المزوّدين دائمًا تقريبًا رابطًا أساسيًا — شيئًا مثل https://api.poe.com/v1. وذلك لأن أمثلة الشيفرة لديهم تستخدم OpenAI SDK، الذي يُلحق /chat/completions نيابةً عنك خلف الكواليس.
لكن حقل API URL في SurfMind لا يفعل ذلك عنك. فهو يتوقع نقطة النهاية الكاملة. لذا عليك إضافة المسار بنفسك:
- الرابط الأساسي من الوثائق:
https://api.poe.com/v1 - ما تلصقه في SurfMind:
https://api.poe.com/v1/chat/completions
والفكرة نفسها تنطبق على حقل Models URL (المستخدَم لسرد النماذج المتاحة تلقائيًا): خذ الأساس وأضف /models ← https://api.poe.com/v1/models.
زلّتان مرتبطتان بذلك:
- تكرار
/v1. إن كان الأساس ينتهي أصلًا بـ/v1، فلا تضِف آخر. فـ.../v1/v1/chat/completionsيعطي خطأ 404. - الشرطات المائلة الزائدة في النهاية. قد يفشل
.../chat/completions/بشرطة مائلة في نهايته على بعض الخوادم. فاحذفها.
الخطأ رقم 4: عدم تطابق الـ Models URL مع الـ API URL
الـ Models URL اختياري. وهو نقطة النهاية التي يستدعيها SurfMind لجلب قائمة النماذج التي يقدّمها المزوّد، لكي يعرضها في قائمة منسدلة بدلًا من إجبارك على كتابة الأسماء. وإن لم تظهر نماذجك في أداة الاختيار بعد الحفظ، فهذا الحقل عادةً هو السبب. وعليه أن يتبع اللهجة نفسها لنقطة نهاية الدردشة:
| اللهجة | الـ Models URL |
|---|---|
| Ollama (الأصلي) | http://localhost:11434/api/tags |
| المتوافق مع OpenAI (الجميع غيره) | https://<host>/v1/models |
من الأخطاء الشائعة الخلط بينهما — استخدام /api/tags مع مزوّد متوافق مع OpenAI، أو /v1/models مع إعداد Ollama الأصلي الجاهز. وإن استخدمت Ollama preset، فهذا الحقل مملوء لك بشكل صحيح؛ فاتركه كما هو.
متى تتركه فارغًا: بعض المزوّدين لا يوفّرون نقطة نهاية عامة لسرد النماذج، أو يحجبونها. وهذا لا بأس به — اترك Models URL فارغًا واكتب معرّف النموذج الدقيق بنفسك في حقل النموذج (راجع الخطأ رقم 7). وستظل الدردشة تعمل؛ لكنك لن تحصل على القائمة المنسدلة المملوءة تلقائيًا.
الخطأ رقم 5: الـ API Key Header (الـ Bearer مقابل x-api-key)
تحدّد القائمة المنسدلة API Key Header كيفية إرفاق مفتاحك بالطلب. واختيار الخطأ منها يعطيك 401 Unauthorized حتى مع مفتاح صالح تمامًا. وهناك ثلاثة خيارات:
| API Key Header | ما يرسله SurfMind | استخدمه لـ |
|---|---|---|
| None | لا شيء | النماذج المحلية لا تحتاج عادةً إلى مصادقة، لكن يجدر التأكد من إعدادك الفعلي. |
| Authorization | Authorization: Bearer <your key> |
كل مزوّد سحابي تقريبًا: Poe، z.ai، Together، Groq، DeepSeek، Mistral، Fireworks، xAI، AWS Bedrock. وهذا هو الخيار الافتراضي للواجهات المتوافقة مع OpenAI. |
| x-api-key | x-api-key: <your key> |
الواجهات على نمط Anthropic وحفنة من المزوّدين الذين يتوقعون ترويسة مفتاح خام بدلًا من رمز Bearer. |
ثم يأخذ حقل API Key المفتاح نفسه فقط:
- لا تكتب كلمة
Bearer— فـ SurfMind يضيفها عند اختيارك Authorization. - لا تترك مسافة زائدة في النهاية (سبب شائع بشكل مفاجئ لأخطاء 401).
- بالنسبة إلى النماذج المحلية، اتركه فارغًا. (LM Studio هو الاستثناء — فهو يطلب قيمةً غير فارغة مهما كانت؛ ووثائقه الخاصة تستخدم
lm-studio.)
إن لم تكن متأكدًا من الترويسة التي يستخدمها مزوّد ما: فإن 99% من المزوّدين المتوافقين مع OpenAI يستخدمون Authorization. ولا تلجأ إلى x-api-key إلا إذا أظهرت وثائق المزوّد صراحةً ترويسة x-api-key. أما زلت تحصل على 401؟ فأعِد توليد المفتاح، وتحقّق جيدًا من اختيار الترويسة، وتأكّد من عدم وجود مسافة شاردة.
الخطأ رقم 6: الـ CORS — العقبة الخاصة بالنماذج المحلية فقط
ترفض المتصفحات استدعاء خادم محلي ما لم يسمح ذلك الخادم صراحةً بالطلبات الواردة من الإضافة. وهذه عقبة تواجه الإعدادات المحلية تحديدًا (فالمزوّدون الخارجيون يسمحون بذلك أصلًا).
Ollama: شغّله مع تمكين وصول المتصفح:
# Mac/Linux OLLAMA_ORIGINS="*" ollama serve # Windows (PowerShell) $env:OLLAMA_ORIGINS="*"; ollama serve"port 11434 already in use"؟ تطبيق Ollama الخلفي يعمل بالفعل. أغلِقه أولًا (شريط القوائم على Mac، وعلبة النظام على Windows)، ثم شغّل الأمر أعلاه.
LM Studio: في تبويب Developer / الخادم المحلي، فعّل Enable CORS قبل بدء الخادم.
نقطة دقيقة أخرى: إن لم يتصل localhost، فجرّب 127.0.0.1 بدلًا منه (أو العكس). فعلى بعض الأنظمة لا يُحلّان بالطريقة نفسها.
الخطأ رقم 7: اسم النموذج يجب أن يتطابق تمامًا
بمجرد اتصالك، يجب أن يتطابق اسم النموذج الذي تختاره مع ما يتوقعه المزوّد — تطابقًا تامًا، بما في ذلك حالة الأحرف. وهذه عقبة يقع فيها كثيرون مع المزوّدين الذين لا يسردون النماذج تلقائيًا، أو الذين يستخدمون تسمية غير مألوفة:
- Poe يستخدم أسماء بوتات على نمط العرض مثل
Claude-Sonnet-4.6وGPT-5.4— انسخها تمامًا كما تظهر على Poe. - z.ai يستخدم معرّفات مثل
glm-4.6وglm-5. - Together AI يستخدم معرّفات بمساحة اسم:
meta-llama/Llama-3.3-70B-Instruct-Turbo،deepseek-ai/DeepSeek-V3. - Fireworks يستخدم معرّفًا بمسار كامل:
accounts/fireworks/models/llama-v3p3-70b-instruct.
إن نجح الاتصال لكنك حصلت على "model not found"، فالسبب غالبًا خطأ مطبعي في الاسم أو حالة أحرف خاطئة. وعندما يستطيع SurfMind سرد النماذج تلقائيًا عبر الـ Models URL، اختر من القائمة بدلًا من الكتابة.
مرجع سريع: النماذج المحلية
تعمل كل هذه على جهازك الخاص. افتح تبويب Custom في SurfMind ← Add Custom Models، واختر الإعداد الجاهز المطابق (لدى Ollama إعداده الخاص؛ والبقية تستخدم الإعداد الجاهز العام OpenAI-compatible)، واضبط API Key Header على None. وأسماء المزوّدين روابط تؤدي إلى وثائق إعداد كل أداة.
- API URL:
http://localhost:11434/api/chat - Models URL:
http://localhost:11434/api/tags - مفتاح الـ API: لا شيء
- API URL:
http://localhost:1234/v1/chat/completions - Models URL:
http://localhost:1234/v1/models - مفتاح الـ API: أي قيمة غير فارغة (مثل
lm-studio)
- API URL:
http://localhost:1337/v1/chat/completions - Models URL:
http://localhost:1337/v1/models - مفتاح الـ API: لا شيء (أو مفتاح Jan الخاص بك)
- API URL:
http://localhost:8080/v1/chat/completions - Models URL:
http://localhost:8080/v1/models - مفتاح الـ API: لا شيء (إلا إذا شغّلته عبر
--api-key)
- API URL:
http://localhost:8000/v1/chat/completions - Models URL:
http://localhost:8000/v1/models - مفتاح الـ API: قيمة
--api-keyإن ضبطتها
- API URL:
http://localhost:8080/v1/chat/completions - Models URL:
http://localhost:8080/v1/models - مفتاح الـ API: لا شيء
لا تنسَ خطوة الـ CORS (الخطأ رقم 6) لأيٍّ من هذه. وبالنسبة إلى Ollama تحديدًا، يوجد الشرح الكامل بالصور في دليل Ollama الخاص بنا، وإن كنت تتردد بين الأداتين الأوليين، فراجع Ollama مقابل LM Studio.
مرجع سريع: مزوّدو الذكاء الاصطناعي الشائعون
كل هؤلاء المزوّدين السحابيين يتحدثون الواجهة المتوافقة مع OpenAI. استخدم الإعداد الجاهز العام OpenAI-compatible، واضبط API Key Header على Authorization (فجميعهم يستخدمون رموز Bearer)، والصق مفتاحك. وأسماء المزوّدين روابط تؤدي إلى وثائق واجهة كل مزوّد.
Poe — مفتاح واحد لمئات النماذج (Claude، GPT، Gemini، Llama…)، تُحتسب تكلفته من نقاط اشتراكك في Poe. وأسماء النماذج هي أسماء بوتات على نمط العرض — انسخها تمامًا كما تظهر على Poe (مثل Claude-Sonnet-4.6، GPT-5.4). المفتاح من poe.com ← Settings ← API key.
- API URL:
https://api.poe.com/v1/chat/completions - Models URL:
https://api.poe.com/v1/models
CanopyWave — مزوّد سحابة GPU يقدّم نماذج مفتوحة (Kimi، DeepSeek، Llama، Qwen). المفتاح من لوحة تحكم CanopyWave.
- API URL:
https://inference.canopywave.io/v1/chat/completions - Models URL:
https://inference.canopywave.io/v1/models
z.ai (GLM) — نماذج GLM من Zhipu (glm-4.6، glm-5). انتبه: ينشر z.ai أيضًا نقطة نهاية منفصلة لخطة البرمجة (https://api.z.ai/api/coding/paas/v4) ونقطة نهاية PaaS (https://api.z.ai/api/paas/v4) — استخدم النقطة المتوافقة مع OpenAI أدناه ولا تضِف /v1 إضافيًا.
- API URL:
https://api.z.ai/api/openai/v1/chat/completions - Models URL:
https://api.z.ai/api/openai/v1/models
Together AI — كتالوج كبير من النماذج المفتوحة. معرّفات النماذج طويلة (meta-llama/Llama-3.3-70B-Instruct-Turbo) — انسخها تمامًا من صفحة النماذج في Together.
- API URL:
https://api.together.xyz/v1/chat/completions - Models URL:
https://api.together.xyz/v1/models
Groq — استدلال سريع للغاية. العقبة: المسار هو /openai/v1، لا /v1 فحسب.
- API URL:
https://api.groq.com/openai/v1/chat/completions - Models URL:
https://api.groq.com/openai/v1/models
DeepSeek — النماذج الحالية هي deepseek-v4-flash وdeepseek-v4-pro (والأسماء البديلة الأقدم deepseek-chat / deepseek-reasoner يجري إيقافها — راجع وثائق DeepSeek لأحدث المعلومات). والـ /v1 اختياري؛ إذ يقبل DeepSeek الرابط بوجوده أو بدونه.
- API URL:
https://api.deepseek.com/v1/chat/completions - Models URL:
https://api.deepseek.com/v1/models
Mistral — mistral-large-latest، mistral-small-latest، وغيرها. متوافق قياسيًا مع OpenAI.
- API URL:
https://api.mistral.ai/v1/chat/completions - Models URL:
https://api.mistral.ai/v1/models
Fireworks AI — العقبة: المسار هو /inference/v1، لا /v1. ومعرّفات النماذج تبدو هكذا accounts/fireworks/models/llama-v3p3-70b-instruct.
- API URL:
https://api.fireworks.ai/inference/v1/chat/completions - Models URL:
https://api.fireworks.ai/inference/v1/models
xAI (Grok) — نماذج Grok (grok-4، وغيرها). متوافق قياسيًا مع OpenAI.
- API URL:
https://api.x.ai/v1/chat/completions - Models URL:
https://api.x.ai/v1/models
AWS Bedrock — أصبح لدى Bedrock الآن نقطة نهاية متوافقة مع OpenAI، لكن مع عقبتين: المضيف خاص بكل منطقة (مثل us-west-2) والمسار هو /openai/v1. ويجب أن تستخدم مفتاح Bedrock API (رمز bearer تولّده في وحدة التحكم) — لا مفاتيح وصول AWS العادية / SigV4. ومعرّفات النماذج تبدو هكذا openai.gpt-oss-120b-1:0.
- API URL:
https://bedrock-runtime.<region>.amazonaws.com/openai/v1/chat/completions - Models URL: اتركه فارغًا — أدخِل معرّف النموذج لاحقًا
ما زال لا يتصل؟ الفرز النهائي
اعمل بالترتيب وفق هذه القائمة:
- افتح مضيف الـ API URL في متصفحك. الخادم المحلي لا يُحمَّل ← فهو لا يعمل، أو المنفذ خاطئ.
- أعِد قراءة المسار. Ollama ←
/api/chat. والجميع غيره ←/v1/chat/completions(أو المسار الخاص بالمزوّد من الجدول). - تأكّد أنك لصقت نقطة النهاية الكاملة، لا الأساس، وأنه لا يوجد
/v1مكرر أو شرطة مائلة زائدة في النهاية. - خطأ 401؟ فالسبب المفتاح أو الترويسة. الترويسة =
Authorization، والمفتاح بلا مسافات، وبلا بادئةBearer. - خطأ 404 "model not found"؟ الاتصال سليم — صحّح اسم النموذج (بحالة الأحرف الدقيقة).
- نموذج محلي والمتصفح يحجب الطلب؟ فعّل CORS (
OLLAMA_ORIGINS="*"أو مفتاح LM Studio)، وجرّب127.0.0.1مقابلlocalhost.
هذا التسلسل يحلّ الغالبية العظمى من الإعدادات.
ما زلت بحاجة إلى مساعدة؟
إن كنت قد عملت بقائمة التحقق وما زال مزوّدك يرفض الاتصال، راسلنا عبر البريد على wave@surfmind.ai مع ذكر المزوّد الذي تحاول استخدامه والخطأ الذي تراه. وسنساعدك على إتمام الاتصال.
أتممت الاتصال؟ افتح SurfMind على الصفحة التالية التي كنت ستقرؤها وشغّل نموذجك.
المنشورات الأخيرة
عرض الكل
ذكاء اصطناعي خاص في Firefox: شغّل النماذج المحلية بلا أي قياس عن بُعد
أضِف مساعد ذكاء اصطناعي خاصًّا إلى Firefox يعمل على نماذج محلية، فلا يغادر محتوى صفحتك جهازك أبدًا. لا قياس عن بُعد، ولا سحابة، ولا تنازل.

أفضل امتدادات المتصفح لنماذج الذكاء الاصطناعي المحلية في 2026 (Ollama وLM Studio وأكثر)
أفضل امتدادات المتصفح لتشغيل نماذج الذكاء الاصطناعي المحلية في 2026، من الأشرطة الجانبية المصقولة التي تجمع المحلي والسحابي إلى أدوات Ollama مفتوحة المصدر. دردش مع أي صفحة، بخصوصية.
Ollama مقابل LM Studio: أي أداة ذكاء اصطناعي محلي تناسبك؟
مقارنة عملية وخالية من المبالغة بين Ollama وLM Studio لتشغيل نماذج الذكاء الاصطناعي محليًا في 2026، بالإضافة إلى كيفية استخدام أي منهما للدردشة مع أي صفحة ويب.